Dify 是一款开源的大模型应用开发平台,旨在帮助开发者快速构建生产级生成式 AI 应用。在Dify 本地化部署中,知识库功能是实现企业级 AI 应用的核心能力。本文介绍基于版本 1.5.1 搭建知识库全流程解析,包括以下内容:
1. Dify基本概念
2. Dify本地部署
3. 基于Dify的知识库搭建
一、Dify基本概念
Dify 是一款开源的大模型应用开发平台,旨在帮助开发者快速构建生产级生成式 AI 应用。它集成了模型管理、提示词工程、数据检索、工作流编排和运维监控等核心功能,支持数百种开源及商业大模型(如 Llama3、GPT-4、Claude 等),并提供可视化工作流设计、RAG(检索增强生成)管道、Agent 智能体框架等特色能力。其核心特点包括:
1. 低代码/无代码界面:通过可视化编排 Prompt、连接知识库、配置 Agent 工作流,降低 AI 开发门槛。
2. 技术栈整合:内置 RAG 管道、多模型支持(如 OpenAI、本地模型)、可观测性工具,避免重复开发基础组件。
3. 开源与自托管:代码完全开放,支持 Docker 私有化部署,确保数据隐私与合规性。
二、Dify本地部署
1. Docker部署
可参考文章基于DeepSeek+RAGFlow的企业知识库搭建中Docker部署步骤。
2. Dify部署
硬件要求:CPU ≥ 2 核,RAM ≥ 4GB(推荐 8GB 以上以运行中等模型)
# 克隆仓库git clone https://github.com/langgenius/dify.gitcd dify/docker# 复制环境配置cp .env.example .env# 启动容器sudo docker compose up -d
验证服务:访问 http://localhost/install,初始化管理员账号。
3. 模型配置
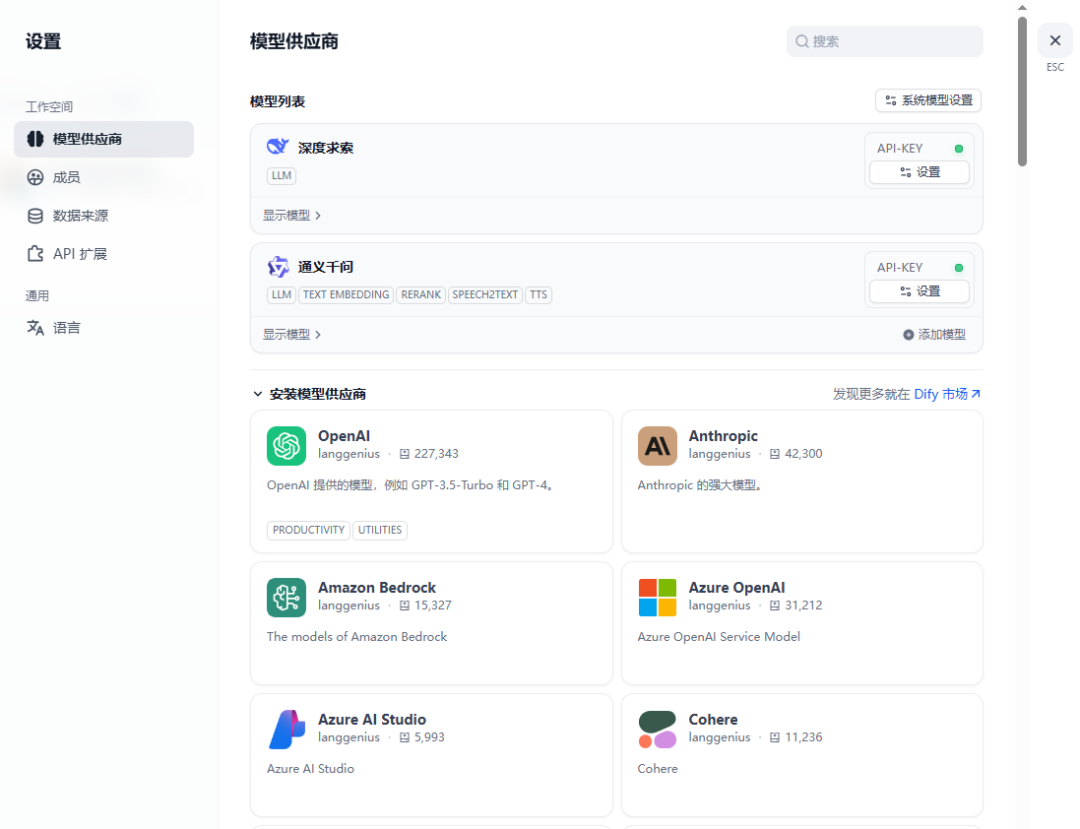
在“设置”—“模型供应商”中自定义配置所需的大模型API-KEY,类型包括Chat、Text Embedding、Rerank模型。
三、基于Dify的知识库搭建
1. Dify知识库介绍
Dify 知识库系统通过RAG(检索增强生成)技术实现,核心流程:
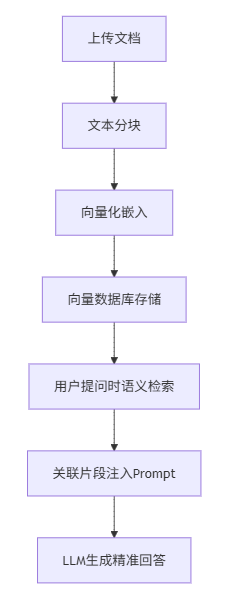
LLM 接收到用户的问题后,将首先基于关键词在知识库内检索内容。知识库将根据关键词,召回相关度排名较高的内容区块,向 LLM 提供关键上下文以辅助其生成更加精准的回答。
开发者可以通过此方式确保 LLM 不仅仅依赖于训练数据中的知识,还能够处理来自实时文档和数据库的动态数据,从而提高回答的准确性和相关性。
支持多种文本类型,例如:
-
长文本内容(TXT、Markdown、DOCX、HTML、JSON 甚至是 PDF)
-
结构化数据(CSV、Excel 等)
-
在线数据源(网页爬虫、Notion 等)
将文件上传至“知识库”即可自动完成数据处理。如果内部已建有独立知识库,可以通过连接外部知识库与 Dify 建立连接。
2. 知识库搭建
“知识库”—“创建知识库”—“选择数据源”,选择作为知识库的来源。
2.1 指定分段模式
知识库支持两种分段模式:通用模式 与 父子模式。如果你是首次创建知识库,建议选择父子模式。
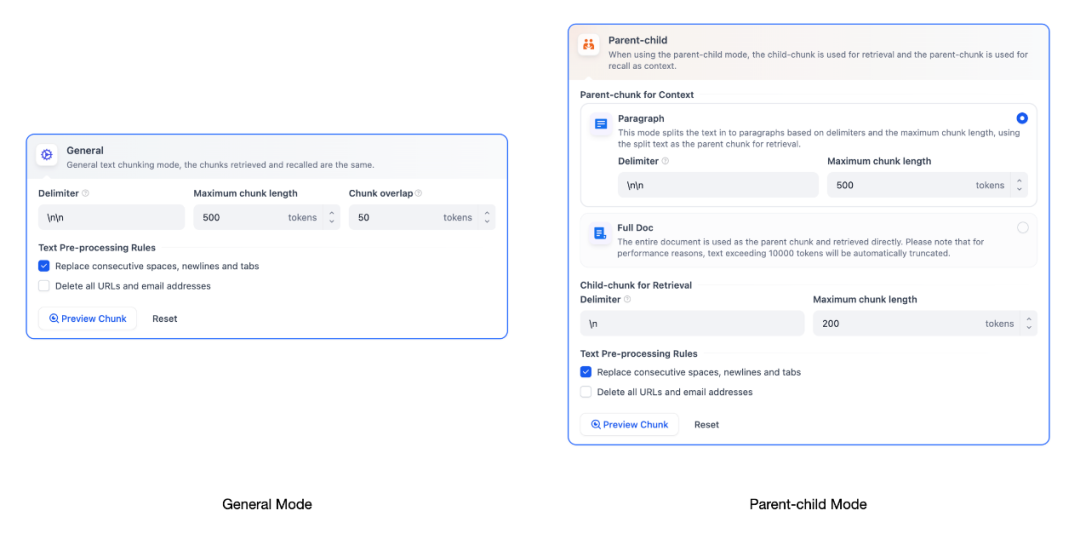
(1)通用模式
系统按照用户自定义的规则将内容拆分为独立的分段,在该模式下,需要根据不同的文档格式或场景要求,参考以下设置项,设置文本的分段规则。
分段标识符:如n,可以遵循正则表达式语法自定义分块规则,系统将在文本出现分段标识符时自动执行分段。下图是不同语法的文本分段效果:
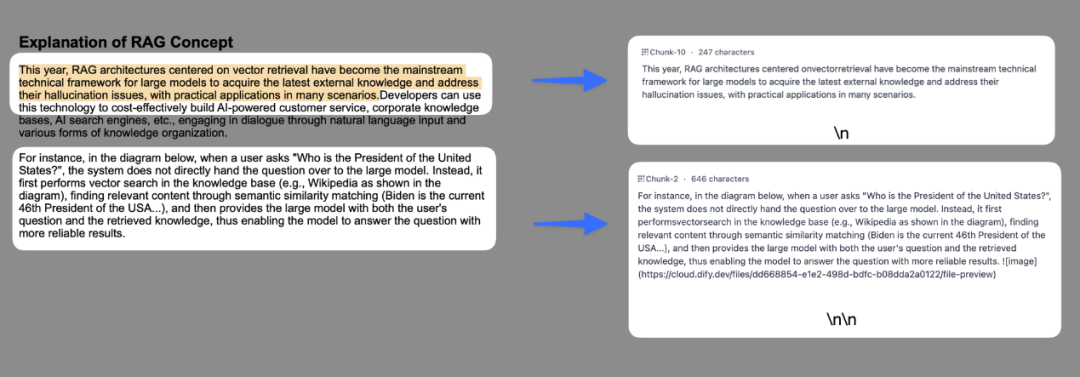
分段最大长度:指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 500 Tokens,分段长度的最大上限为 4000 Tokens;
分段重叠长度:指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%;
配置完成后,点击“预览区块”即可查看分段后的效果。可以直观的看到每个区块的字符数。如果重新修改了分段规则,需要重新点击按钮以查看新的内容分段。
若同时批量上传了多个文档,轻点顶部的文档标题,快速切换并查看其它文档的分段效果。
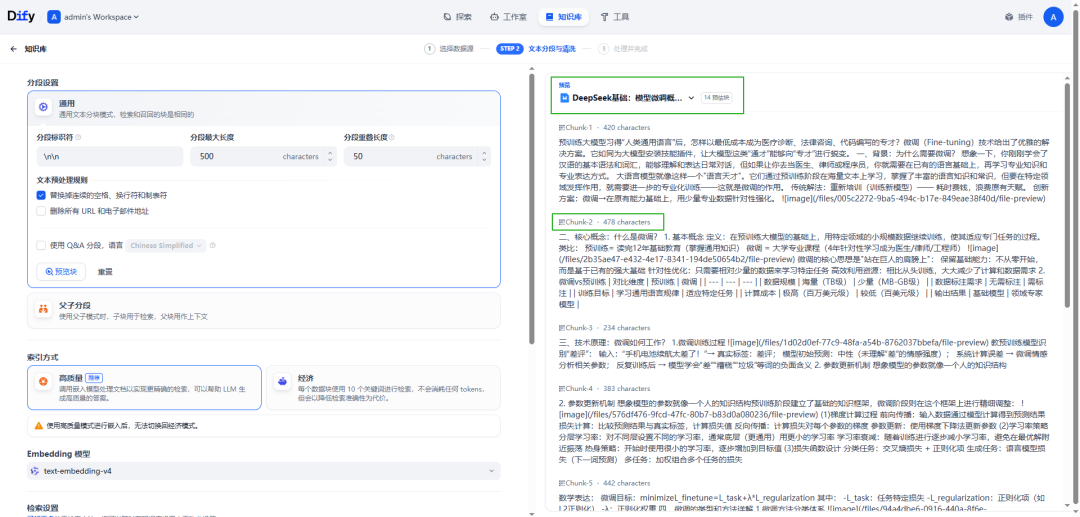
(2)父子模式
与通用模式相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。可以通过设置分隔符和最大长度来自定义父子区块的分段方式。
例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
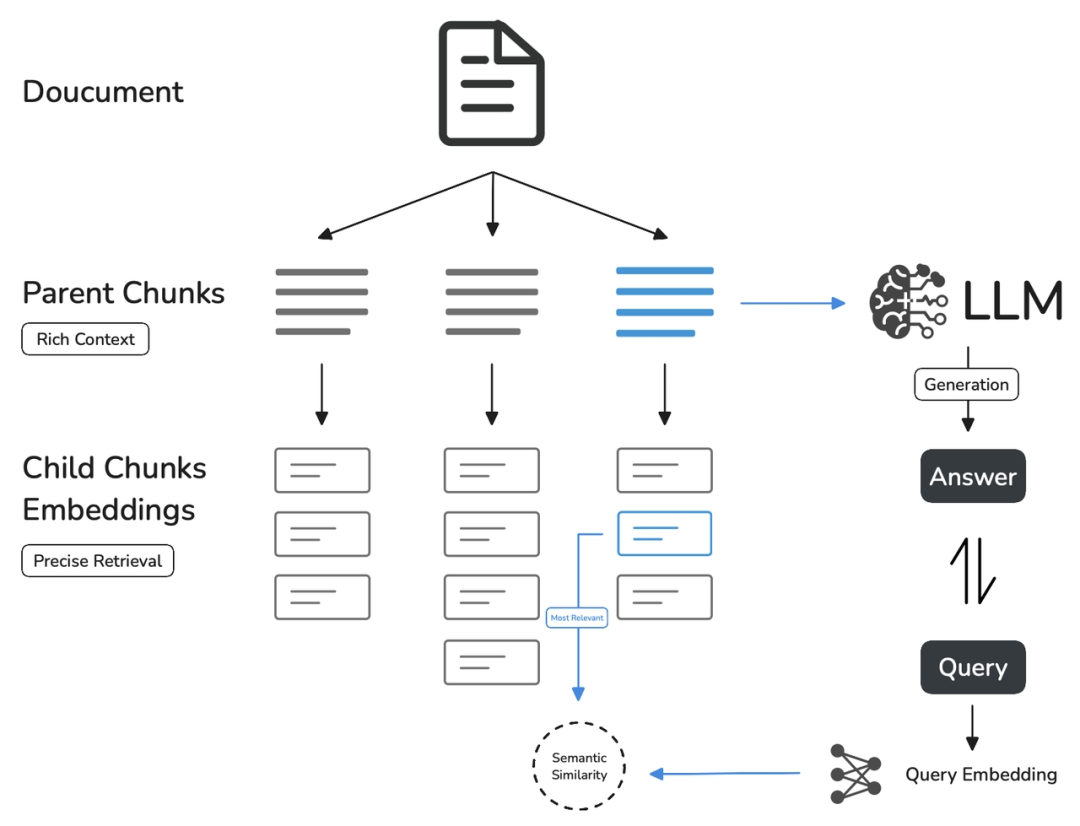
其基本机制包括:
子分段匹配查询:
-
将文档拆分为较小、集中的信息单元(例如一句话),更加精准地匹配用户所输入的问题。
-
子分段能快速提供与用户需求最相关的初步结果。
父分段提供上下文:
-
将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
-
父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
配置完成后,点击“预览区块”即可查看分段后的效果。可以查看父分段的整体字符数。背景标蓝的字符为子分块,同时显示当前子段的字符数。
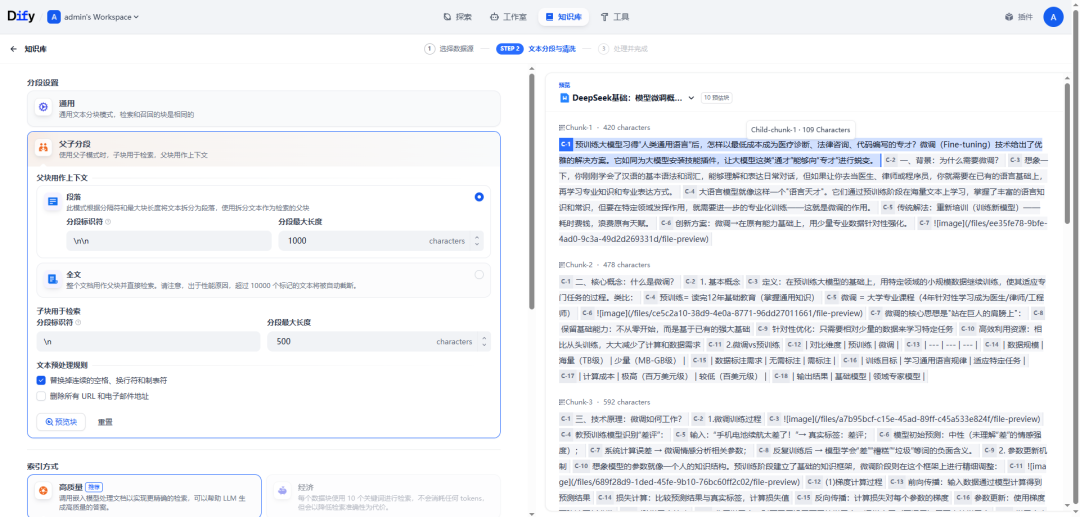
(3)两种模式的区别
两者的主要区别在于内容区块的分段形式。通用模式的分段结果为多个独立的内容分段,而父子模式采用双层结构进行内容分段,即单个父分段的内容(文档全文或段落)内包含多个子分段内容(句子)。
不同的分段方式将影响LLM对于知识库内容的检索效果。在相同文档中,采用父子检索所提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。
2.2 索引方法与检索设置
提供高质量与经济两种索引方法,其中分别提供不同的检索设置选项:
在高质量模式下,使用Embedding嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;使得用户问题与文本之间的匹配能够更加精准。
将内容块向量化并录入至数据库后,需要通过有效的检索方式调取与用户问题相匹配的内容块。高质量模式提供向量检索、全文检索和混合检索三种检索设置。
(1)向量检索
定义:向量化用户输入的问题并生成查询文本的数学向量,比较查询向量与知识库内对应的文本向量间的距离,寻找相邻的分段内容。
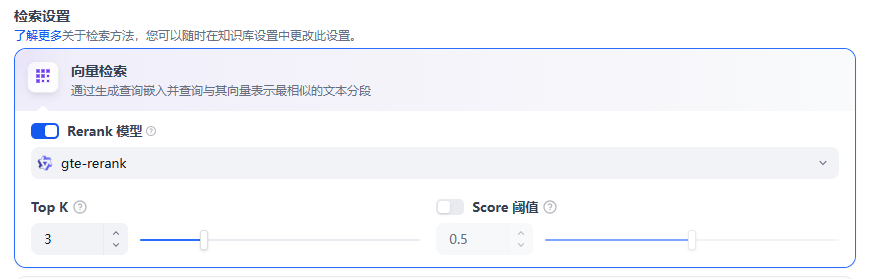
Rerank模型:默认关闭。开启后将使用第三方Rerank模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助LLM获取更加精确的内容,辅助其提升输出的质量。
TopK:用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
Score阈值:用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
(2)全文检索
定义:关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
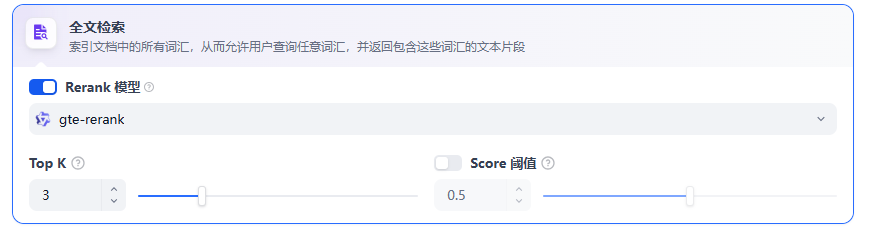
Rerank模型:默认关闭。开启后将使用第三方Rerank模型再一次重排序由全文检索召回的内容分段,以优化排序结果。向LLM发送经过重排序的分段,辅助其提升输出的内容质量。
(3)混合检索
定义:同时执行全文检索和向量检索,或Rerank模型,从查询结果中选择匹配用户问题的最佳结果。
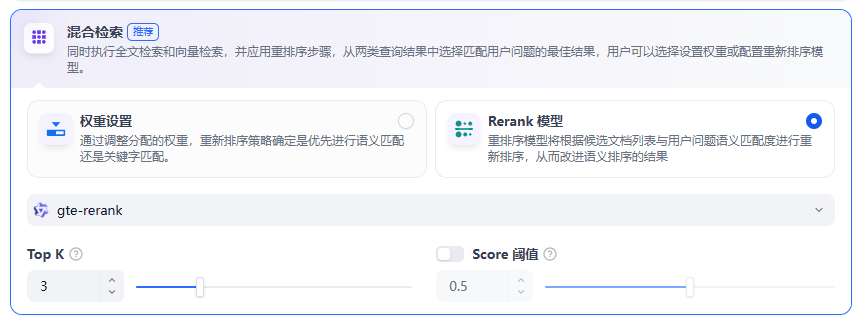
权重设置:允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
Rerank模型:默认关闭,开启后将使用第三方Rerank模型再一次重排序由混合检索召回的内容分段,以优化排序结果。
3. 知识库使用
运用Dify内置的应用模板创建基于知识库的问答系统,“工作室”—“从应用模板创建”—“Knowledge Retreival + Chatbot”:
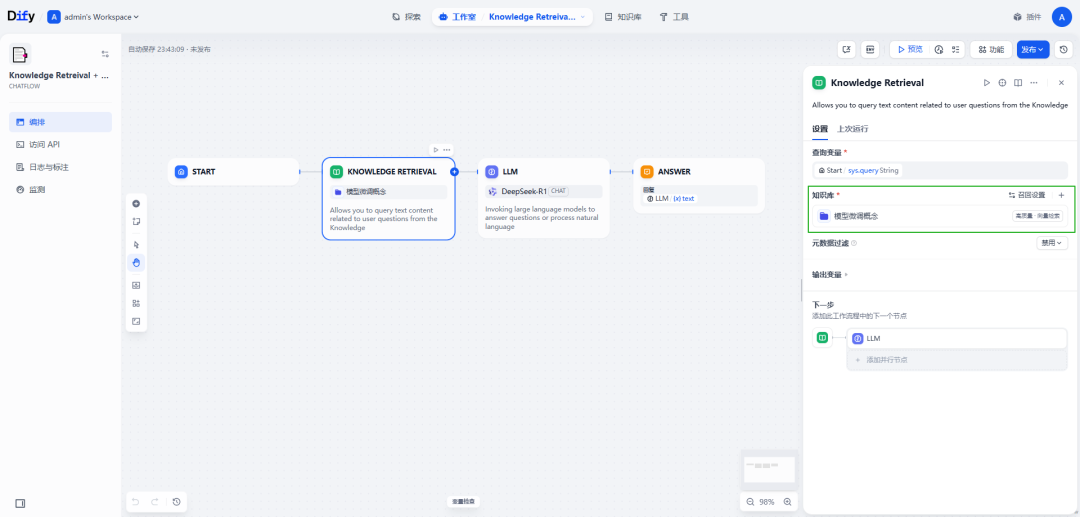
在“Knowledge Retrieval”组件配置知识库名称和召回设置:
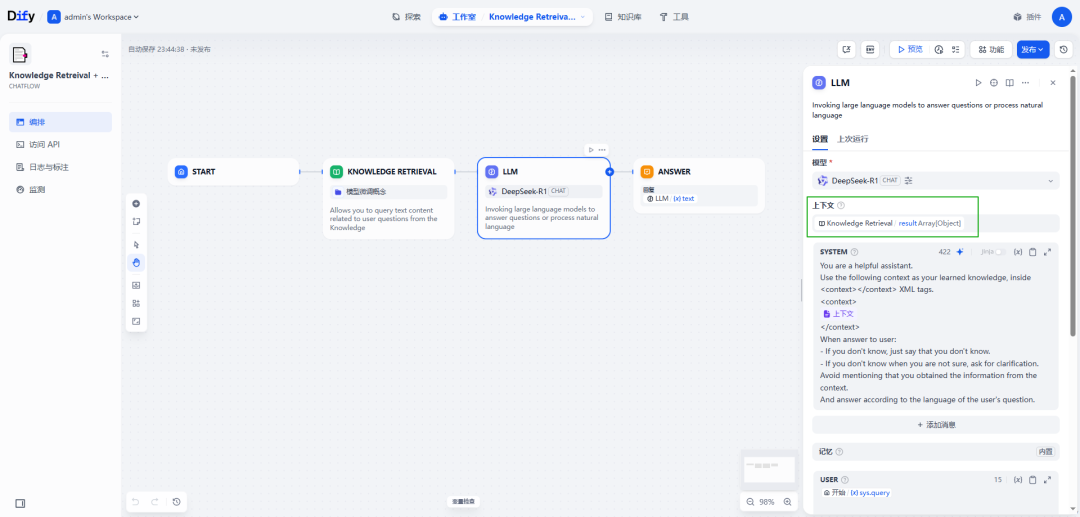
在“LLM”组件中设置模型类型及将知识库检索结果作为上下文:
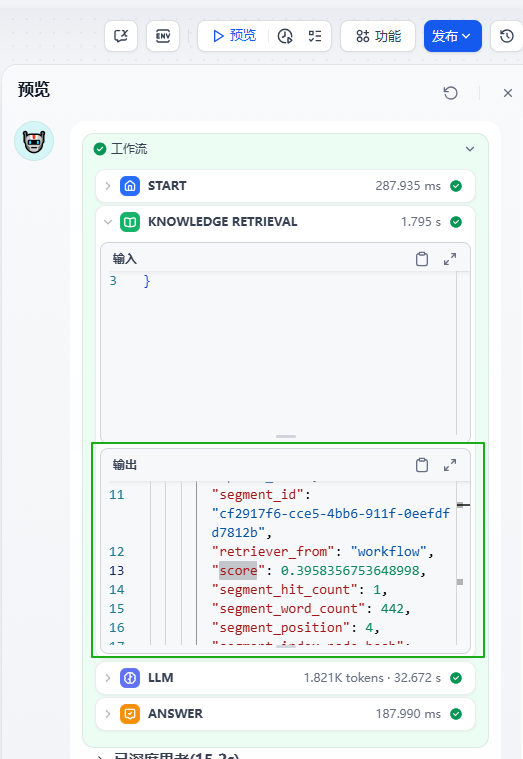
设置完成后进行预览测试,可在工作流中查看每一步的运行情况,在“Knowledge Retrieval”输出中可查看知识库的检索结果:
总结
Dify通过知识库索引优化、多模态支持和动态参数校验,构建了企业级 AI 知识库的完整技术栈。其本地化部署方案在数据安全(GDPR/HIPAA 合规)、性能和成本上具有显著优势。无论是医疗、金融还是制造业,均可通过 Dify 实现私有数据的智能管理与精准应用。建议企业结合自身业务场景,灵活运用 FireCrawl 爬取、Xinference 模型部署等扩展方案,打造贴合需求的行业级知识库系统。
本篇文章来源于微信公众号: 数据思考笔记

文章评论