作为短视频创作者,你是否经常遇到这样的困扰: 如果你有以上任何一个困扰,那么你需要一个对标账号拆解的智能体,帮助你系统地分析对标账号,让创作少走弯路。 对标账号拆解简单来说,就是找到行业内做得好的账号,仔细研究他们为什么成功,然后学习他们的优点。 这个过程包括分析目标账号的定位策略(他们针对什么人群)、人设塑造(他们在观众心中树立什么形象)、选题方向(他们做什么内容)、内容结构(他们怎么组织内容)和变现路径(他们怎么赚钱)等多个维度。 通过对标账号拆解,内容创作者可以: 需要注意的是,对标账号拆解不是简单的模仿和复制,而是要在理解对方成功要素的基础上,结合自身特点进行创新和优化,打造出具有个性化的优质内容。 就像学习绘画一样,先临摹大师作品学习技巧,再发展出自己的风格。盲目抄袭只会让你成为别人的影子,无法形成自己的独特价值。 整个智能体搭建过程,主要分为两个步骤: 登录Coze官网,在“资源库-工作流”里新建一个空白工作流,取名“benchmark_analysis”。 这里通常用来定义工作流启动时需要的输入参数,比如对标账号的视频链接(video_url)。 通过“视频搜索”插件的“douyin_data”工具,获取对标账号视频信息。 通过“视频搜索”插件的“get_user_video_all”工具,批量获取视频列表。 这个环节会使用批处理节点,批处理体内部会执行两个节点: 1.单个获取视频详情 通过“视频搜索”插件的“douyin_data”工具,单个获取视频详情。 2.根据分享链接下载视频 通过“视频下载”插件的“download_video”工具,下载视频。 3.批量提取视频文案 通过“字幕获取”插件的“generate_video_captions_sync”工具,提取视频文案。 4.将视频文案信息整合进视频列表中 系统提示词如下: 通过“飞书云文档”插件的“create_document”工具,创建飞书云文档。 最后输出对标拆解报告的文档链接,完事~ 工作流只是一个自动化脚本,如果想在对话中直接使用,就需要封装成一个 AI 智能体。 在 Coze 中进入“智能体”版块,新建一个 智能体,取个好记的名字,比如“对标账号拆解智能体”。 编辑该智能体的“人设与逻辑”,告诉它自己是一个专业的对标账号拆解助手。提示词如下: 把之前的“benchmark_analysis”工作流加进来,让智能体在合适的时机自动调用它。、 在右侧面板中进行对话测试,输入个短视频的链接,看智能体是否能正确完成对标拆解,并成功写入飞书文档。 确认无误后点击“发布”,就可以把这个智能体发布到飞书或其他渠道。 通过对标账号拆解智能体,我们成功生成了一份结构清晰、内容完善的对标拆解报告。 本文我们构建了一个对标账号拆解智能体。 这个智能体能够自动化提取目标账号的视频内容、互动数据和受众反馈,为内容创作者提供全方位的竞品分析视角。 从抓取视频数据、解析文案内容,到生成结构化报告,每一步都经过精心设计,确保分析结果既全面又精准。 这种自动化工作流程大大简化了传统人工拆解的繁琐步骤,让分析过程变得轻松高效。 对创作者来说,这是一个实用的学习对标的工具,能快速掌握成功账号的运营要点。 你不必再费时费力地一个视频一个视频地看,也不用担心遗漏重要信息。 智能体会系统地总结出对方的内容策略、互动规律和增长技巧,让你一目了然。 以往可能需要团队几天才能完成的分析工作,智能体现在只需要几分钟就能生成专业报告。 这意味着创作者可以将更多精力投入到内容创作本身,而不是耗费在繁琐的分析工作上。 如果你觉得这篇文章有帮助,别忘了点赞、关注、收藏哟,传统美德不能丢哟~
1、对标账号拆解智能体
2、搭建智能体的工作流
1)创建空白工作流

2)开始节点

3)获取对标账号视频信息



4)根据用户ID,批量获取视频列表

5)批量获取视频详细信息





async defmain(args: Args) -> Output:
# 如果 args.params 为 None,则使用空字典
params = args.params or {}
# 从 params 提取子项,如果为 None,则使用空字典
aweme = params.get("aweme") or {}
text_data = params.get("text_data") or {}
# 为 aweme 添加字段 text
aweme["text"] = text_data.get("content", "")
aweme_detail = params.get("aweme_detail", {})
aweme["aweme_detail"] = aweme_detail
# 构造返回值
ret: Output = {
"aweme": aweme
}
return ret6)通过python代码,将信息整理为格式化的数据

async defmain(args: Args) -> Output:
# 1. 先安全地获取 params
params = getattr(args, "params", {}) # 如果 args 或 params 不存在,就给空字典
ifnotisinstance(params, dict):
return [] # 如果 params 不是字典,直接返回空列表
# 2. 安全地获取 aweme_list
aweme_list = params.get("aweme_list", [])
ifnotisinstance(aweme_list, list):
return [] # 如果 aweme_list 不是列表,也直接返回空列表
result = []
# 3. 遍历 aweme_list,依次处理
for aweme in aweme_list:
# 如果当前 aweme 非字典类型,直接跳过
ifnotisinstance(aweme, dict):
continue
# 4. 安全获取 share_info 和 statistics
share_info = aweme.get("share_info", {}) ifisinstance(aweme.get("share_info"), dict) else {}
statistics = aweme.get("statistics", {}) ifisinstance(aweme.get("statistics"), dict) else {}
text = aweme.get("text", "")
# 5. 提取各字段信息,并在取值时加默认值
video_id = statistics.get("aweme_id", "")
title = share_info.get("share_title", "")
link = share_info.get("share_url", "")
digg_count = statistics.get("digg_count", 0)
comment_count = statistics.get("comment_count", 0)
collect_count = statistics.get("collect_count", 0)
share_count = statistics.get("share_count", 0)
# 6. 获取 aweme_detail 并判空
aweme_detail = aweme.get("aweme_detail", {}) ifisinstance(aweme.get("aweme_detail"), dict) else {}
# 获取作者信息
author_info = aweme_detail.get("author", {}) ifisinstance(aweme_detail.get("author"), dict) else {}
author_name = author_info.get("nickname", "")
signature = author_info.get("signature", "")
sec_uid = author_info.get("sec_uid", "")
# 7. 获取时间和时长,这里可以进一步做类型检查,防止计算时报错
raw_create_time = aweme_detail.get("create_time", 0)
create_time_ms = raw_create_time * 1000ifisinstance(raw_create_time, int) else0
raw_duration = aweme_detail.get("duration", 0)
duration_sec = raw_duration / 1000ifisinstance(raw_duration, (int, float)) else0
# 8. 组装返回数据
item_dict = {
"fields": {
"视频ID": video_id,
"标题": title.strip(),
"文案": text,
"链接": {
"text": "查看视频",
"link": link.strip(),
},
"点赞数": digg_count,
"评论数": comment_count,
"收藏数": collect_count,
"分享数": share_count,
"作者": author_name,
"用户简介": signature,
"用户ID": sec_uid,
"发布日期": create_time_ms,
"时长": duration_sec
}
}
result.append(item_dict)
return result7)通过大模型节点,使用DeepSeek生成拆解报表。

根据对标账号的视频列表信息
{{input}}
自动生成结构化的报告:
- 账号基本信息:名称、简介
- 定位:账号核心受众、差异化价值
- 人设:IP形象、语言风格
- 选题方向:爆款主题分类、发布时间规律
- 内容结构:开场、叙事节奏、结尾引导
- 变现路径:广告、带货、课程等模式分析8)飞书文档插件:创建飞书文档
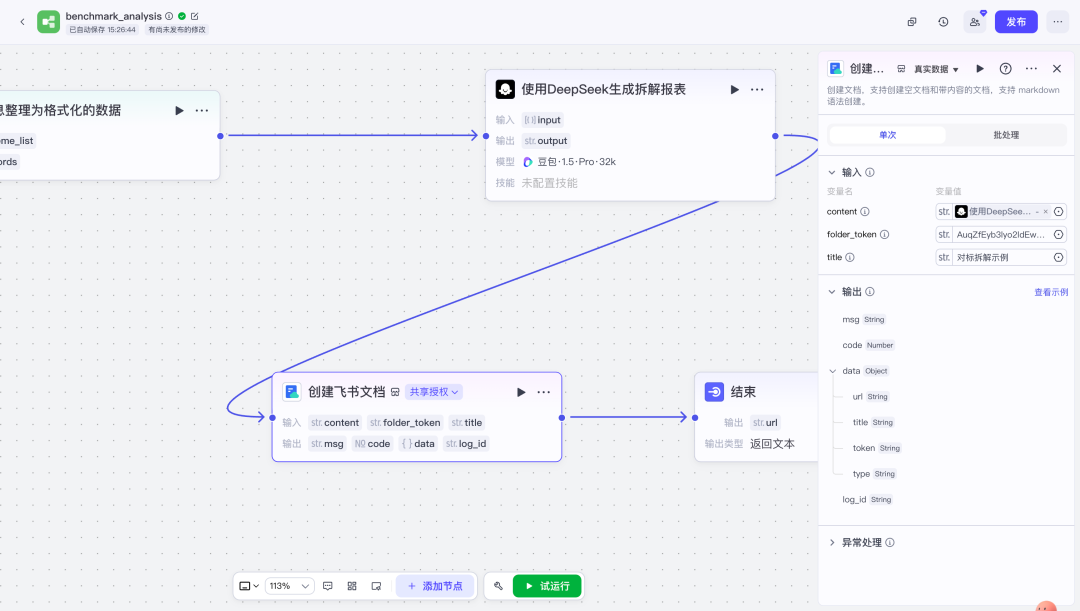

9)结束节点

3、创建智能体
1)新建智能体
2)人设与逻辑
当用户输入视频 url 时,调用 `benchmark_analysis`工作流来生成对标拆解报告。3)绑定工作流

4)测试并发布

5)查看飞书文档中的对标拆解报告

4、小结
本篇文章来源于微信公众号: AI架构师汤师爷

文章评论