一个完全自动化的 RAG (检索增强生成) 数据知识库构建工作流。
你只需要输入一个网站地图 (sitemap) 的网址,按下“执行”,然后就可以泡杯咖啡,静静地看着电脑帮你完成所有工作:自动抓取网页 - AI 清洗整理 - 存成本地 Markdown 文件。
最终效果?就可以将你想要网站的精华内容,都变成了你本地整齐划一的知识库文件!
🛠️ 第一步:准备我们的“瑞士军刀”工具箱
在开始之前,我们需要准备几个强大的工具。别怕,在 Docker 的帮助下,安装它们就像点菜一样简单。
1. n8n:自动化流程的大脑
这是我们整个工作流的核心,一个开源的、可视化的流程自动化工具。你可以把它想象成一个超级强大的“if...then...that”,但功能要多得多。
安装 n8n:
为了方便后续文件保存,我们使用以下命令,将本地目录挂载到 n8n 容器中。
https://n8n.io/
# 确保你本地有这个目录,比如 /Users/你的用户名/opt/n8n_data
mkdir -p ~/opt/n8n_data运行 n8n 容器
# 停止并删除现有容器
docker stop n8n
docker rm n8n
# 创建本地目录
mkdir -p ~/opt/n8n_data
# 更新最新版本
docker pull n8nio/n8n:latest
# 使用绑定挂载重新运行容器
# 在运行前,先确保旧的 n8n 容器已经停止并删除
docker stop n8n
docker rm n8n
docker run -d --restart unless-stopped
--name n8n
--dns 8.8.8.8
-e GENERIC_TIMEZONE=Asia/Shanghai
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
-e N8N_RUNNERS_ENABLED=true
-p 5678:5678
-e N8N_DEFAULT_LOCALE=zh-CN
-e N8N_SECURE_COOKIE=false
-v n8n_data:/home/node/.n8n
-v /Users/jackfeng/opt/n8n_data:/data
-v /Users/jackfeng/tools/server/dist:/usr/local/lib/node_modules/n8n/node_modules/n8n-editor-ui/dist
n8nio/n8n
命令解析:
-v n8n_data:/home/node/.n8n:(用于n8n核心数据) 使用命名卷 n8n_data 来持久化 n8n 的配置和工作流。
-v /Users/jackfeng/opt/n8n_data:/data:(用于工作流文件) 这是新增的关键一行。它将你 Mac 上的 /Users/jackfeng/opt/n8n_data 目录映射到容器内部的 /data 目录。
如果你没有映射,那么你也可以复制卷内容:
docker cp n8n:/home/node/ /Users/jackfeng/opt/n8n_data
/data/{{ $('If').item.json.markdown.split('n')[0]}}.md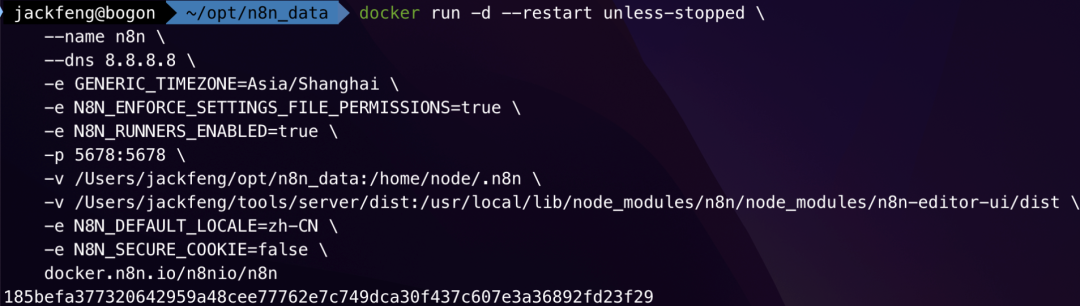
关键点: -v ~/opt/n8n_data:/data 这行命令,就是将你电脑上的 n8n_data 文件夹映射到容器的 /data 目录,这样工作流生成的文件才能被我们直接在电脑上看到。
2. Crawl4ai:网页内容抓取专家
一个专门为 AI 设计的爬虫工具,能把任何网页优雅地转换成干净的 Markdown 格式,是构建知识库数据源的完美选择。
地址: https://github.com/unclecode/crawl4ai
安装 Crawl4ai:
docker run -d
-p 11235:11235
--name crawl4ai
-e CRAWL4AI_API_TOKEN=datascience
-v ./crawl4ai_data:/data
--restart unless-stopped
unclecode/crawl4ai:latest-e CRAWL4AI_API_TOKEN=datascience这里我们设置了一个访问令牌datascience,后面在 n8n 里会用到它。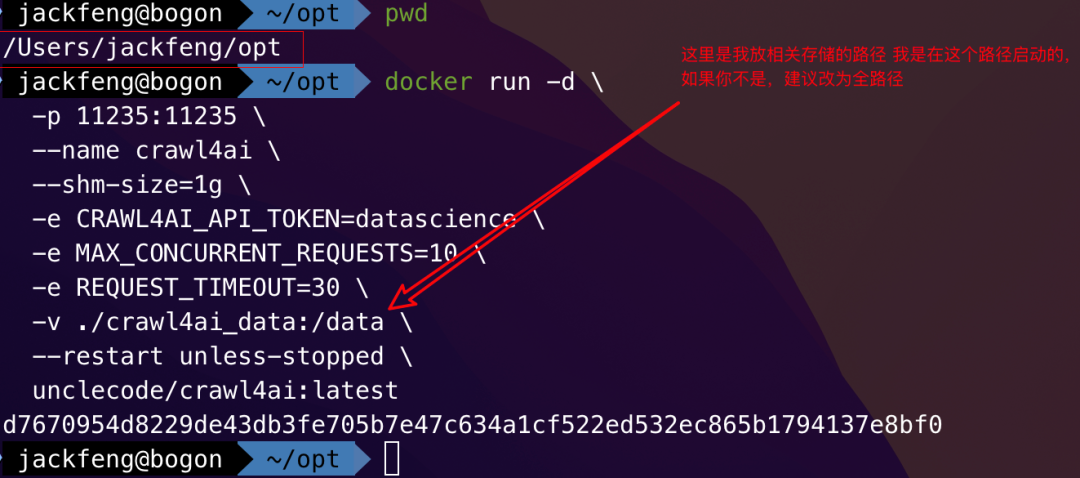
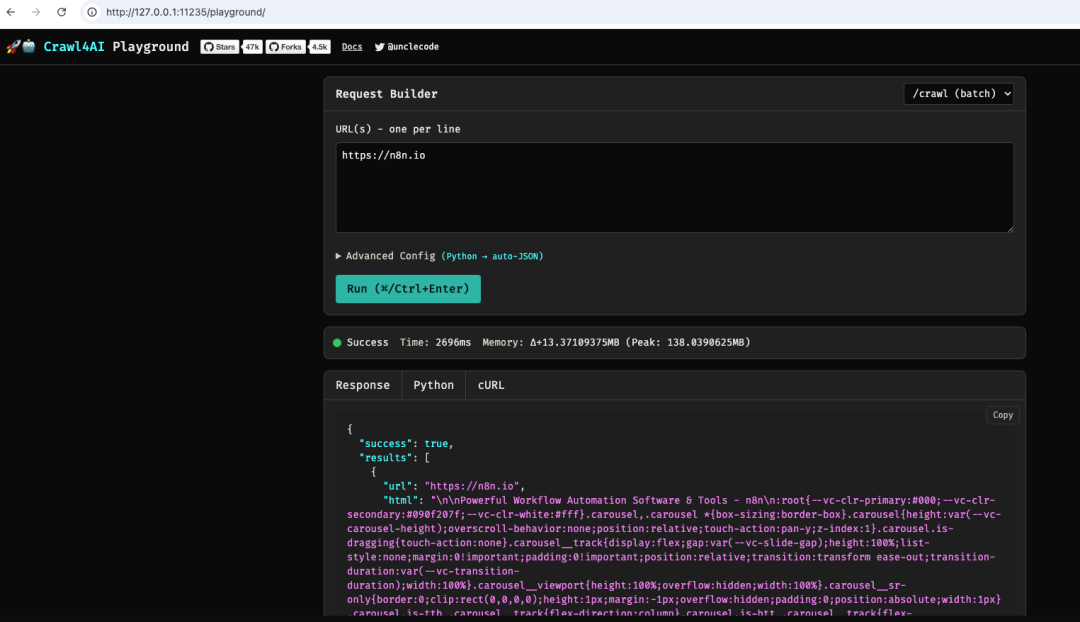
测试crawl4ai站点是否正常
以n8n站点为例测试一下,是可以正常使用的
站点地图:https://n8n.io/sitemap_index.xml
君子协议: 在网站后边添加 robot.txt
生成sitemap网站
https://www.xml-sitemaps.com/

生成完整的页面浏览量
https://www.xml-sitemaps.com/download/n8n.io-da7db434a/sitemap.xml?view=1
这个是所有的n8n的,如果需要自己去用,我们这次主要是想打造完整的知识库,所以我们抓取对应的docs
https://docs.n8n.io/sitemap.xml

Name:
Authorization
Value:
Bearer datascience
3. Ollama & BGE-M3:本地大模型的家
Ollama 可以让你在本地轻松运行各种大语言模型。我们将用它来运行 bge-m3,这是一个强大的嵌入模型,是未来构建 RAG 检索能力的基础。虽然本次工作流主要用它来做知识的“向量化准备”,但它是完整 RAG 链路的关键一环。
https://ollama.com/

可以直接点击下载,也可以使用docker 运行,这里我们使用docker 容器来运行,更多参数可以参考
https://hub.docker.com/r/ollama/ollama
# cpu 模式
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama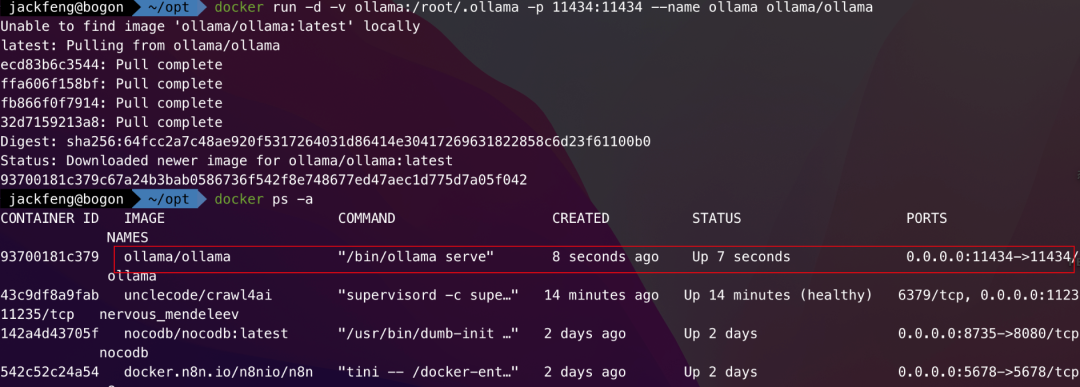

安装 Ollama 进入容器下载模型
进入容器,因为我们是在docker内安装,所以需要进入容器内使用。
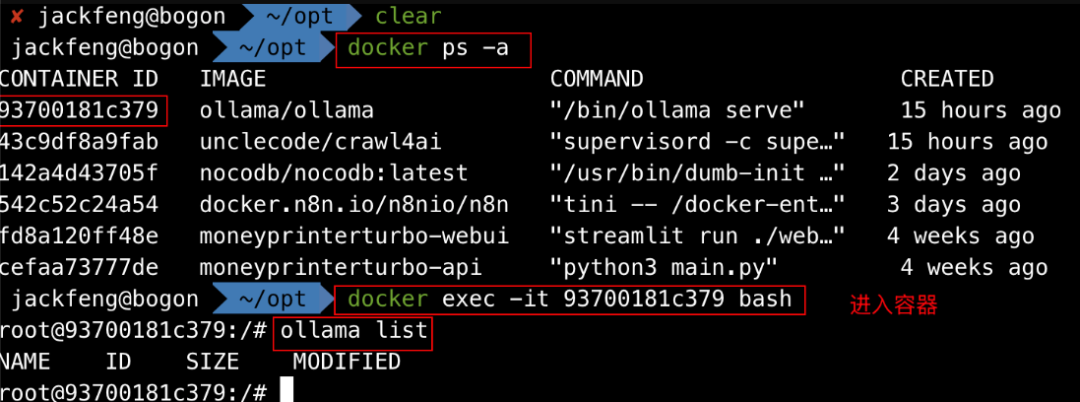
下载安装bge-m3, 这是嵌入式模型,BGE-M3 是 BAAI 推出的一款新机型,以多功能、多语言和多粒度的多功能性而著称。
BGE-M3 基于 XLM-RoBERTa 架构,具有多功能性、多语言性和多粒度的多功能性:
-
• 多功能性:可以同时实现嵌入模型的三种常见检索功能:密集检索、多向量检索、稀疏检索。 -
• 多语言性:可支持100多种工作语言。 -
• 多粒度:它能够处理不同粒度的输入,从短句子到最多 8192 个标记的长文档。
ollama pull bge-m3
看到 Success 字样就说明模型已经准备就绪!
4. Cherry Studio
Cherry Studio 是一款集多模型对话、知识库管理、AI 绘画、翻译等功能于一体的全能 AI 助手平台。
Cherry Studio 高度自定义的设计、强大的扩展能力和友好的用户体验,使其成为专业用户和 AI 爱好者的理想选择。无论是零基础用户还是开发者,都能在 Cherry Studio 中找到适合自己的 AI 功能,提升工作效率和创造力。
下载地址: https://docs.cherry-ai.com/cherry-studio/download
官网: https://www.cherry-ai.com/
5. Docker 容器 IP 地址查询方法总结
1. 容器内部查询
进入容器后执行以下命令查看 hosts 文件:
cat /etc/hosts这会显示当前容器及其链接容器(--link)的 IP 地址。
2. 单容器 IP 查询方法
# 简洁格式
docker inspect -f '{{ .NetworkSettings.IPAddress }}' <container-ID>
# 完整信息
docker inspect <container-ID>
# 支持多网络的格式
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' <container-ID>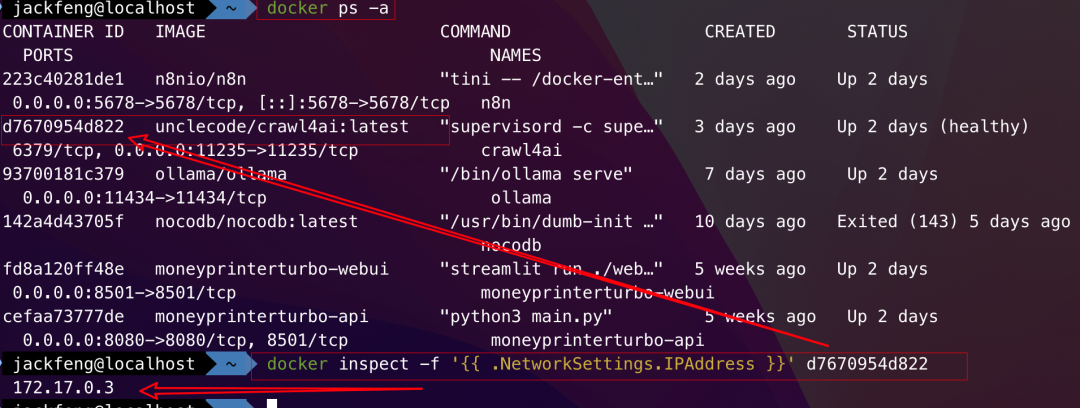
3. 创建快捷函数
将以下函数添加到 ~/.bashrc 文件中:
function docker_ip() {
docker inspect --format '{{ .NetworkSettings.IPAddress }}' "$1"
}然后执行 source ~/.bashrc 使配置生效,使用方式:
docker_ip <container-ID>4. 批量查询容器 IP
# 所有容器名称及其IP
docker inspect -f '{{.Name}} - {{.NetworkSettings.IPAddress}}' $(docker ps -aq)
# 支持docker-compose多网络环境
docker inspect -f '{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq)5. 优化版批量查询命令
docker inspect --format='{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq)使用建议
-
1. 对于单容器查询,推荐使用快捷函数 docker_ip -
2. 在多网络环境中,使用包含 range的命令格式 -
3. 查询所有容器时,注意容器名称前会有 /前缀,这是正常现象
🧠 第二步:搭建全自动工作流
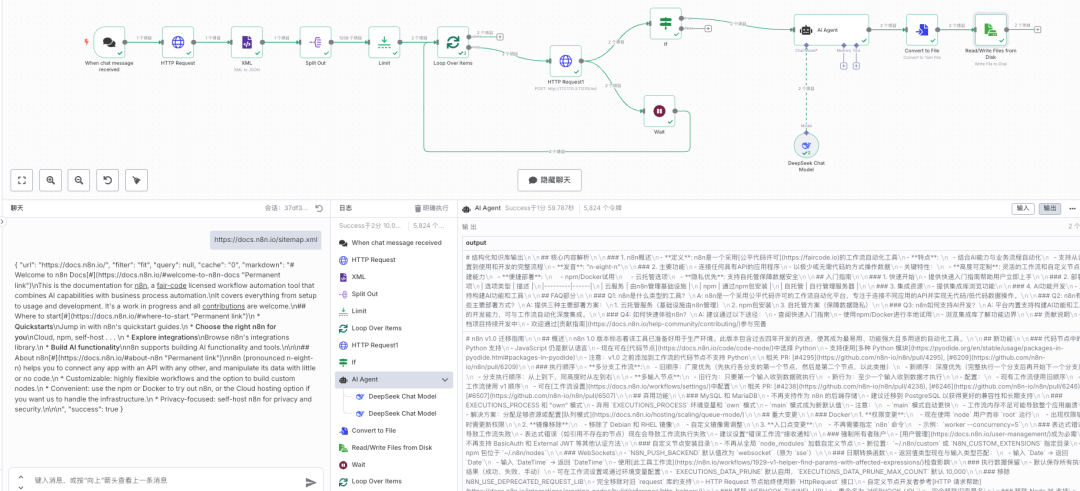
节点 1-4:获取并解析目标网址
-
1. When chat message received (触发器): 工作流的起点。我们在这里输入一个网站的 sitemap.xml地址。例如,我们想抓取 n8n 的官方文档,就输入https://docs.n8n.io/sitemap.xml。 -
2. HTTP Request (获取地图): 向输入的 sitemap 地址发送请求,拿到网站的所有公开页面的列表(XML格式)。 -
3. XML (解析地图): 将上一步获取的 XML 数据,解析成 n8n 能理解的 JSON 结构。 -
4. Split Out (拆分网址): sitemap 里包含了无数个网址,这个节点会把它们一个个拆分开,方便后续单独处理。
节点 5-7:循环抓取网页内容
-
5. Limit (限制数量): 为了测试方便,我们可以先设置只抓取 15 个页面。等工作流验证无误后,再拿掉这个限制。 -
6. Loop Over Items (循环器): 这是工作流的“发动机”,它会带着每个页面的 URL,走一遍后续的抓取和处理流程。 -
7. HTTP Request1 (调用 Crawl4ai): 循环的核心! -
• URL: http://localhost:11235/md(你本地 Crawl4ai 服务的地址) -
• Method: POST -
• Body: {"url": "{{ $json['urlset.url'].loc }}"},这里的{{...}}是 n8n 的表达式,动态地将当前循环到的页面 URL 传给 Crawl4ai。 -
• Authentication: 设置 Header Auth,Value 填入Bearer datascience(就是我们启动 Crawl4ai 时设置的CRAWL4AI_API_TOKEN)。
-
节点 8-10:AI 精加工与结构化
-
8. If (判断): 检查上一步 Crawl4ai 是否成功返回了内容。如果成功,才继续下一步。 -
9. AI Agent (AI 处理核心): 这是工作流的“魔法棒”!我们在这里给 AI (例如 DeepSeek 模型)下达一个非常明确的指令 (Prompt),让它化身为信息整理专家。 给 AI 的角色设定和任务要求 (Prompt 核心思想):
-
• 角色: 你是信息结构化和知识库开发专家。 -
• 任务: -
1. 解析内容: 理解抓取到的 Markdown 数据。 -
2. 结构化整理: 用清晰的标题和层级逻辑组织信息。 -
3. 创建 FAQ: 根据内容提炼出常见问题和答案。 -
4. 提升可读性: 优化排版。 -
5. 翻译: 将内容翻译成中文。 -
6. 纯净输出: 去掉所有多余的解释,只留下整理好的核心数据。
-
-
-
10. DeepSeek Chat Model: 将 AI Agent 的指令和上一步抓取的 Markdown 内容,一起发送给大模型进行处理。
节点 11-13:保存成果
-
11. If1 (再次判断): 确保 AI 处理后有内容输出。 -
12. Convert to File: 将 AI 输出的文本内容转换成文件格式。 -
13. Read/Write Files from Disk (写入磁盘): 这是最后一步!我们将处理好的内容写入到我们之前挂载的本地目录中。 -
• File Name: 使用表达式 /data/{{ $('AI Agent').item.json.output.split('n')[0].replaceAll('#','').replaceAll(' ','').replaceAll('\','') }}.md`。 -
• 这段代码的意思是: 在 /data目录下(也就是你电脑上的~/opt/n8n_data),用 AI 生成内容的第一行作为文件名,并去掉特殊字符,最后以.md格式保存。
-
好了!点击“Execute Workflow”,见证奇迹吧!
运行完成
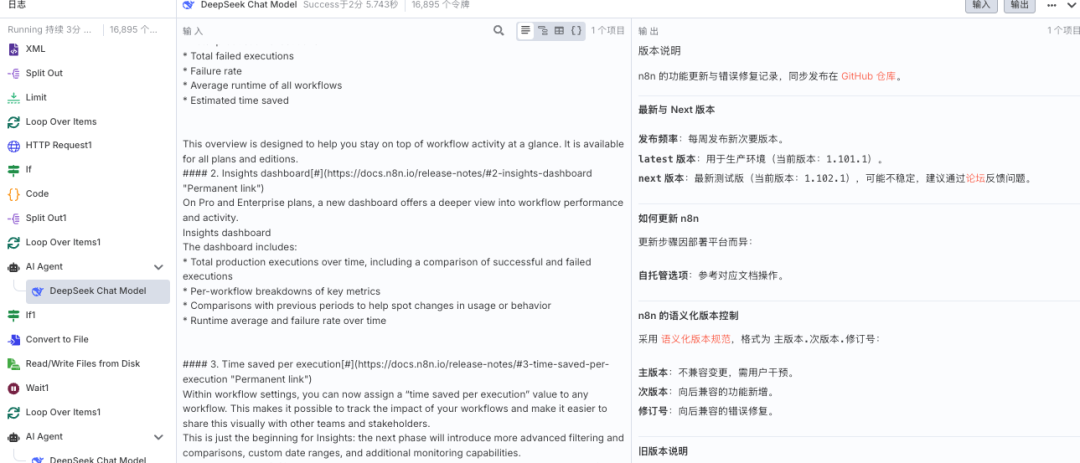
当然这个只是举例说明,如果需要完整的n8n文档,可以访问这个地址即可,https://github.com/n8n-io/n8n-docs/tree/main/docs
🚀 第三步:验收你的知识宝库
执行完毕后,打开你本地的 ~/opt/n8n_data 文件夹,你会发现,所有抓取的网页都已经被 AI 处理得明明白白、整整齐齐,变成了独立的 Markdown 文件。
接下来,你可以用任何支持 Markdown 的知识库软件(如 Obsidian, Logseq, Cherry-ai 等)来管理这些文件。一个强大的、可检索的、完全属于你自己的本地知识库就此诞生!
本地知识库:
https://docs.cherry-ai.com/ 使用这个软件
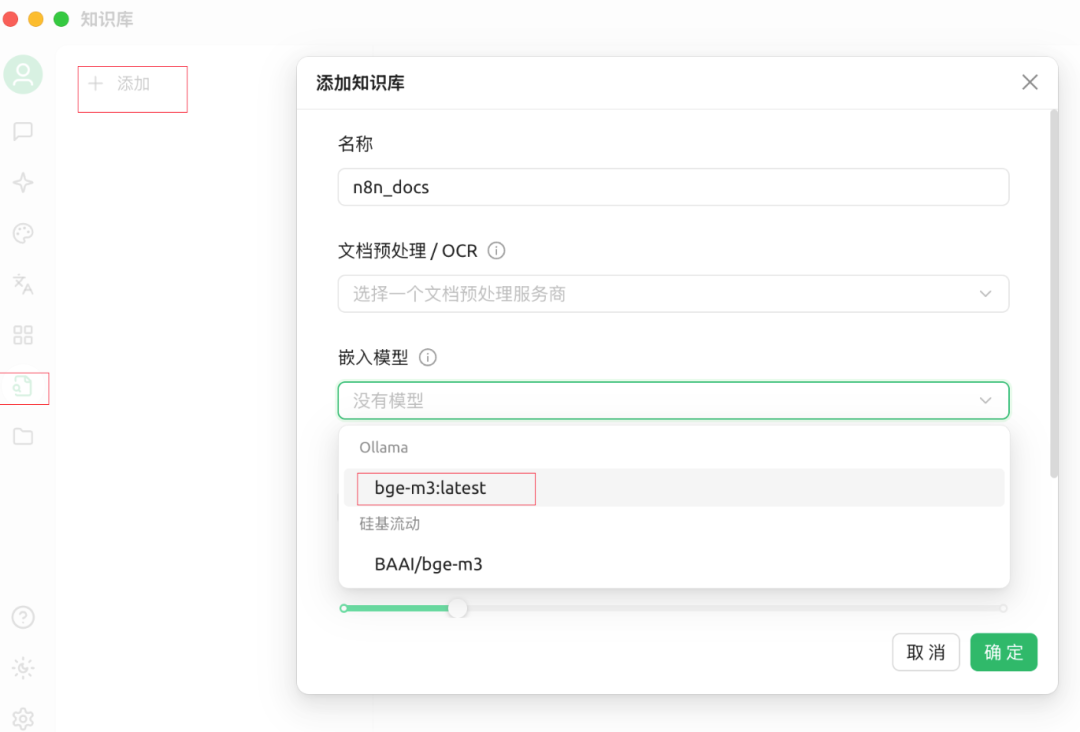
测试使用
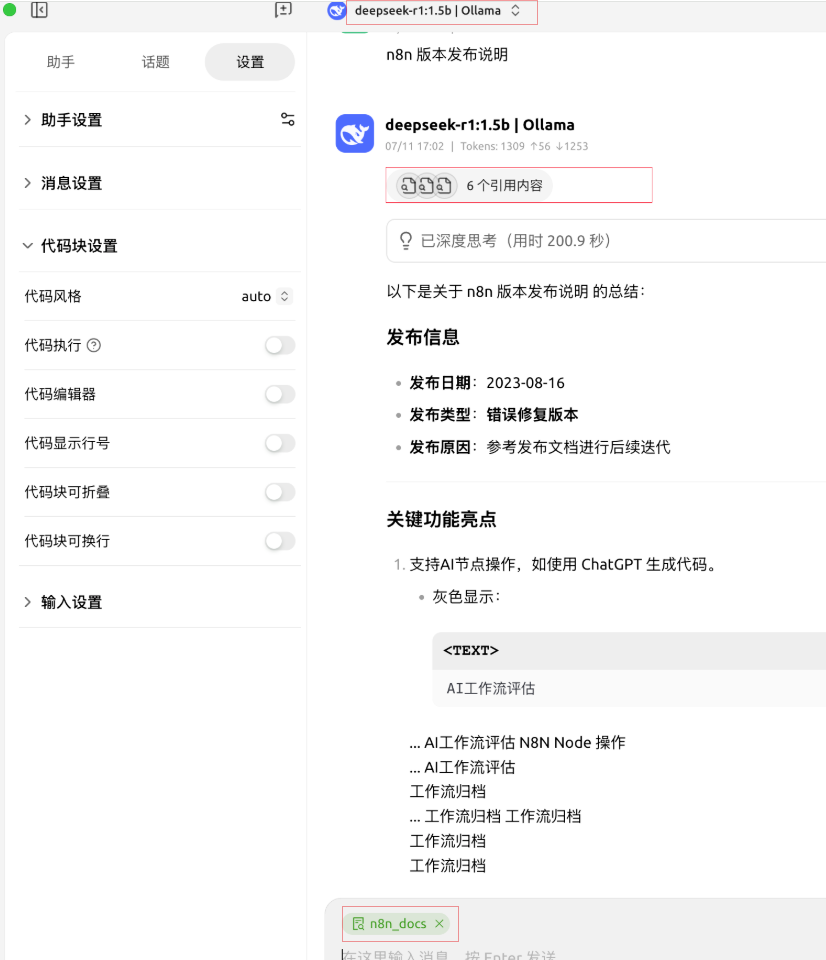
总结
通过组合 n8n 的自动化能力、Crawl4ai 的精准抓取、AI大模型 的智能处理,以及 Docker 的便捷部署,实现了一个看似复杂但其实逻辑清晰的“知识生产线”。
这套工作流的魅力在于:
-
• 全自动: 一次配置,永久受益。 -
• 高度可定制: 你可以抓取任何你想要的网站,也可以修改 AI 的 Prompt 来满足你独特的整理需求。 -
• 本地化与私密性: 所有数据都保存在你的本地,安全可控。
本篇文章来源于微信公众号: DataScience

文章评论