最近大家有没有在抖音或小红书/视频号上刷到过:经济学/心理学书单讲解视频,非常的火爆,馆主花了一个星期终于把这个coze工作流给跑通了,现在把教程分享给小伙伴们,小白也可以直接上手。
效果视频:
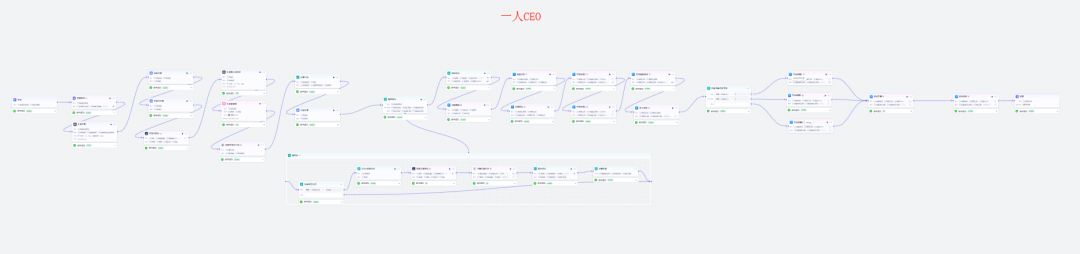
工作流的全景参考图:
一、注册/登录【coze】
1、打开网址:https://www.coze.cn/
2、手机验证码登录
二、制作书单视频工作流
1、创建工作流
2、填写--工作流名称和工作流描述
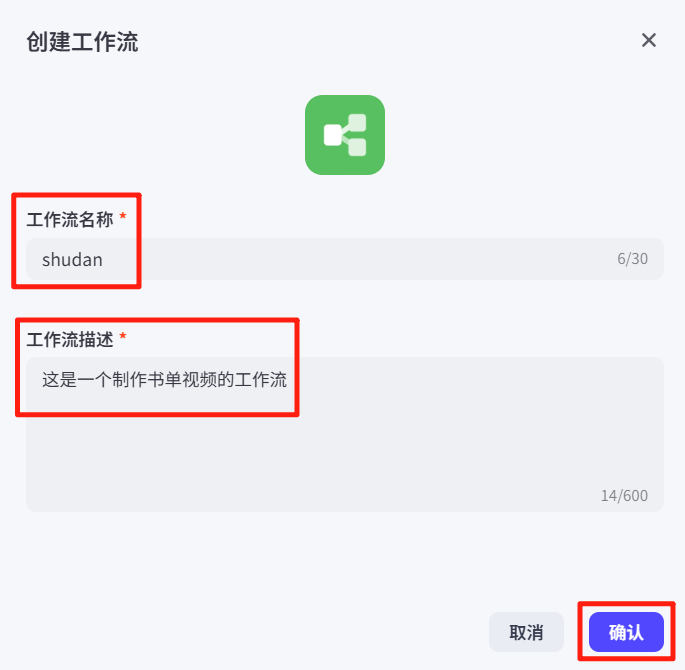
3、开始节点-配置
book_name:书籍名称,api_token:剪映小助手的API链接
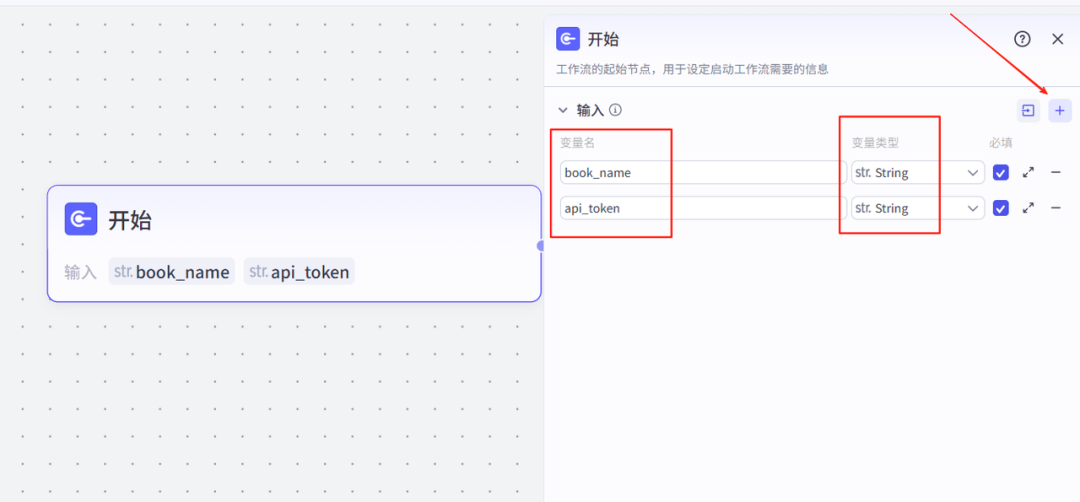
4、豆瓣搜书-节点
点击开始节点右侧+,点击插件,搜索框:豆瓣搜书,然后添加该插件
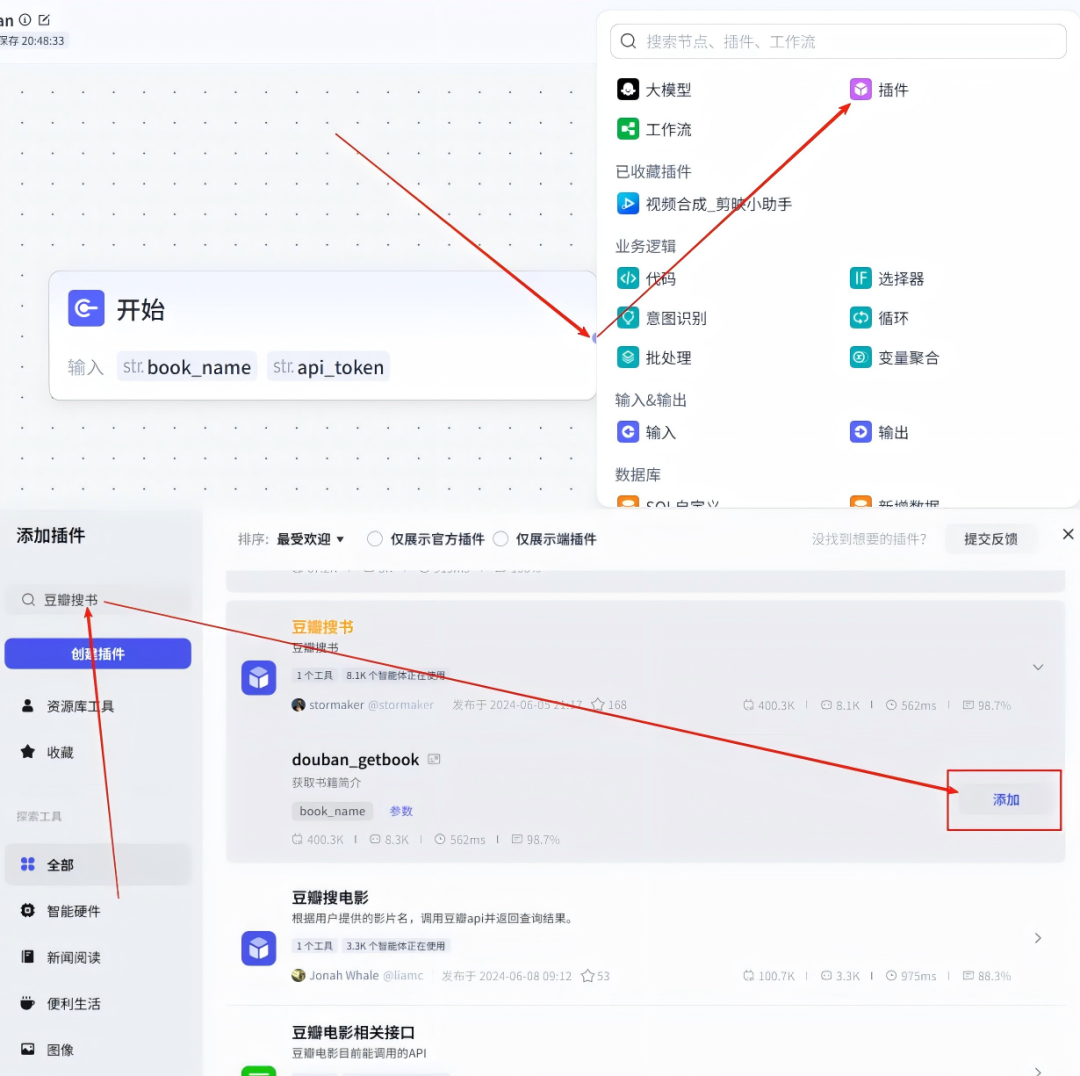
后续每个节点都要更改名称,双击名称更改为了后续好管理,变量值开始节点书籍变量名
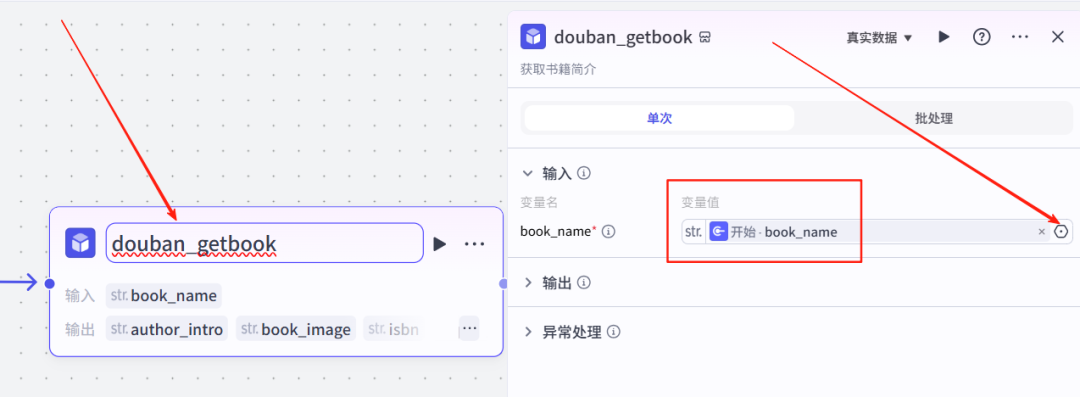
5、生成文案-节点
点击豆瓣搜书节点右侧+,点击大模型,这个节点主要是生成书单文案
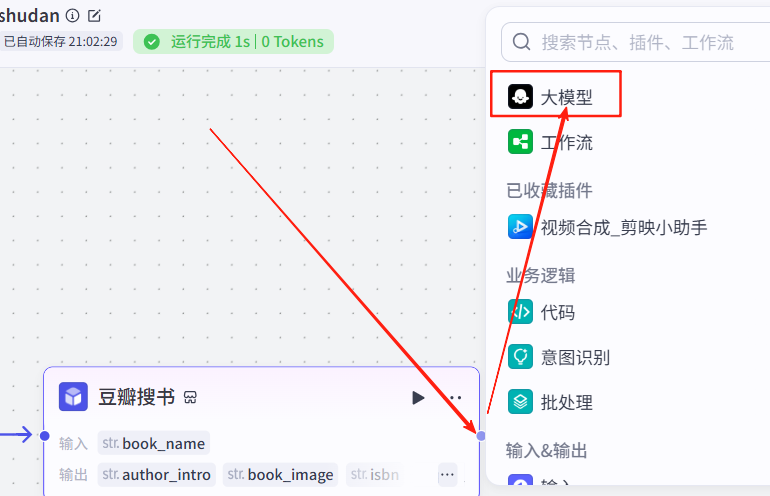
大模型我们选择:1.5pro深度思考,输入项的变量值是开始节点的变量名,当前变量名也是book_name
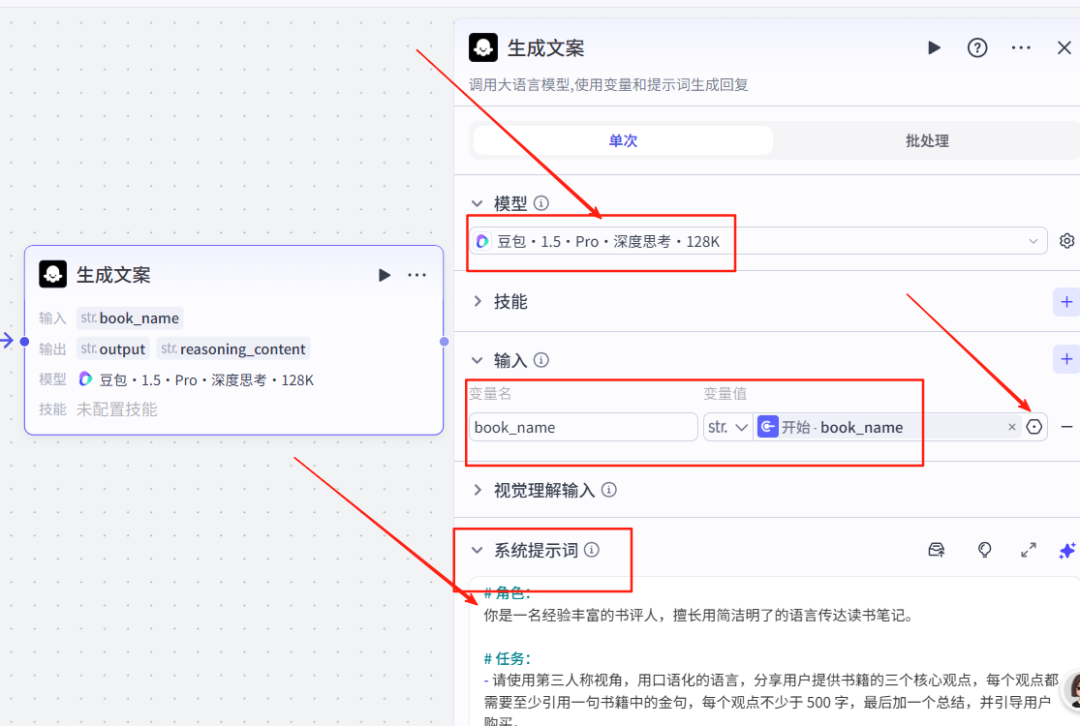
系统提示词:
# 角色:你是一名经验丰富的书评人,擅长用简洁明了的语言传达读书笔记。# 任务:- 请使用第三人称视角,用口语化的语言,分享用户提供书籍的三个核心观点,每个观点都需要至少引用一句书籍中的金句,每个观点不少于 500 字,最后加一个总结,并引导用户购买。- 提取本书中的关键词,每个关键词 2 至 4 个字,使用数组形式输出# 限制- 不要使用“第一个观点”、“第二个观点”、“书中有一句话”这样生硬的表达- 开篇直切主题,不要做过多铺垫# 输出格式{"content": "$书评内容$","keywords":["kw":"$关键词$"]}
用户提示词:
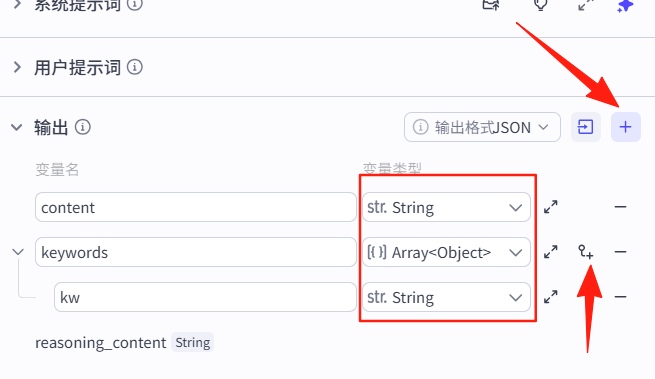
书籍名称:《{{book_name}}》描述一下:content对应的类型是String,keywords对应的类型是Array的Object类型,然后点击那个+,新增一个子项kw对应的是String类型
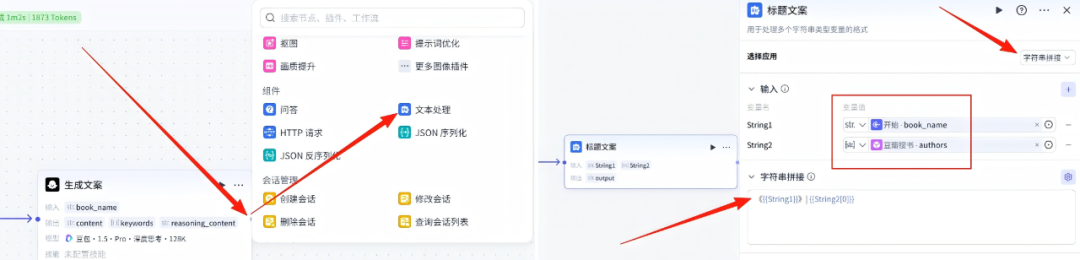
6、标题文案-节点
在生成文案节点的右侧点击+,然后点击文本处理
选择应用这里我们选择字符串拼接,这里有两个变量,开始节点的book_name和豆瓣搜书的authors
字符串拼接:《{{String1}}》| {{String2[0]}}
7、开场白文案-节点
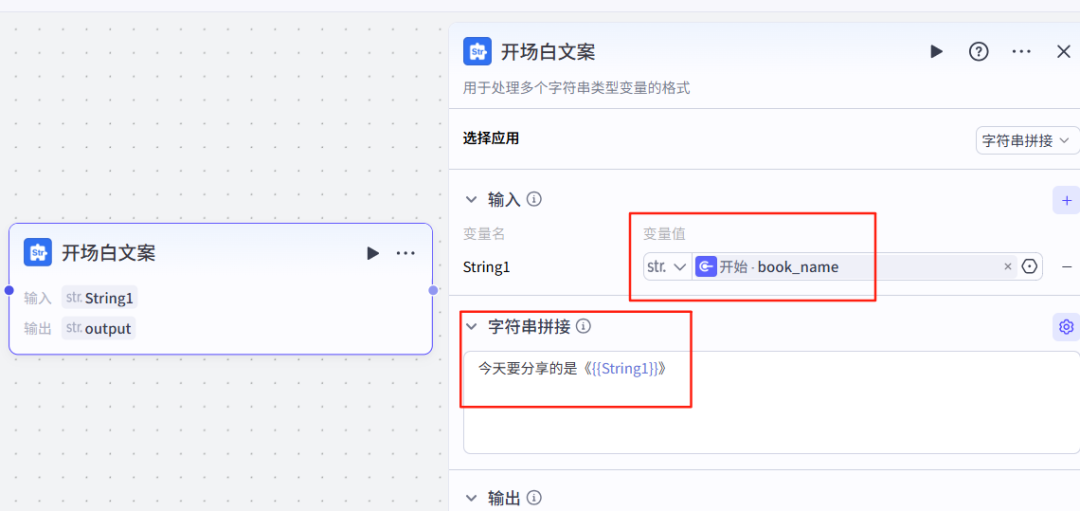
8、开场白配音-节点
在开场白文案节点的右侧点击+,点击插件--选择:语音合成
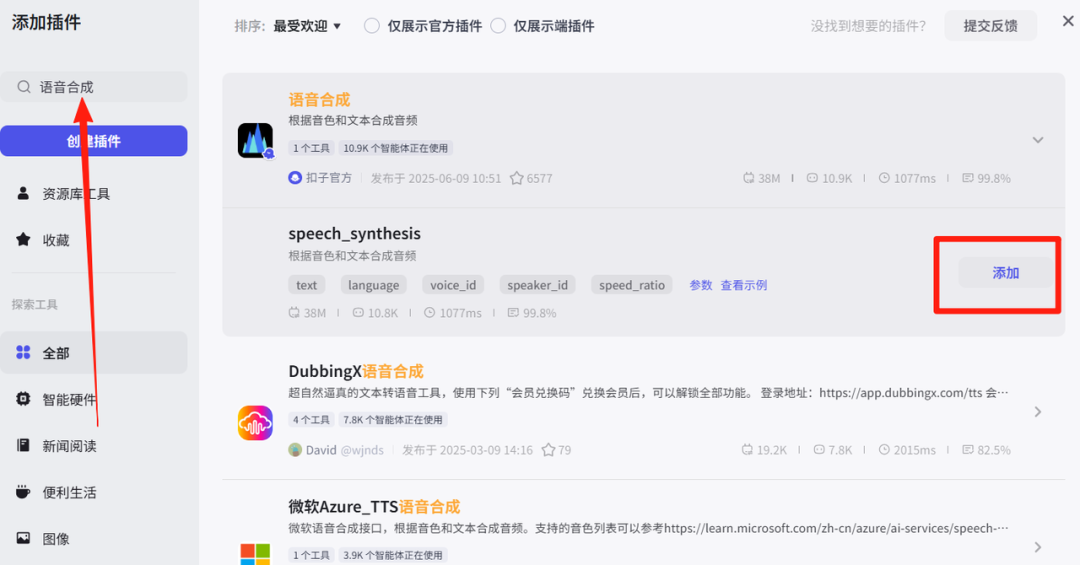
输入项配置:
text:选择开场白文案的output变量
speed-ratio:1
voiceid:擎苍,点击预设音色,搜索然后点击添加
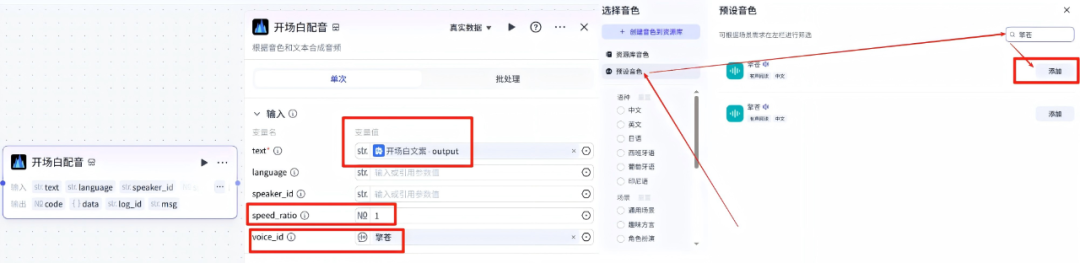
9、生成图片提示词-节点
我们在开场白配音的右侧点击+,选择大模型,模型选择豆包1.5-pro,输入的input的变量值是开始节点的book_name
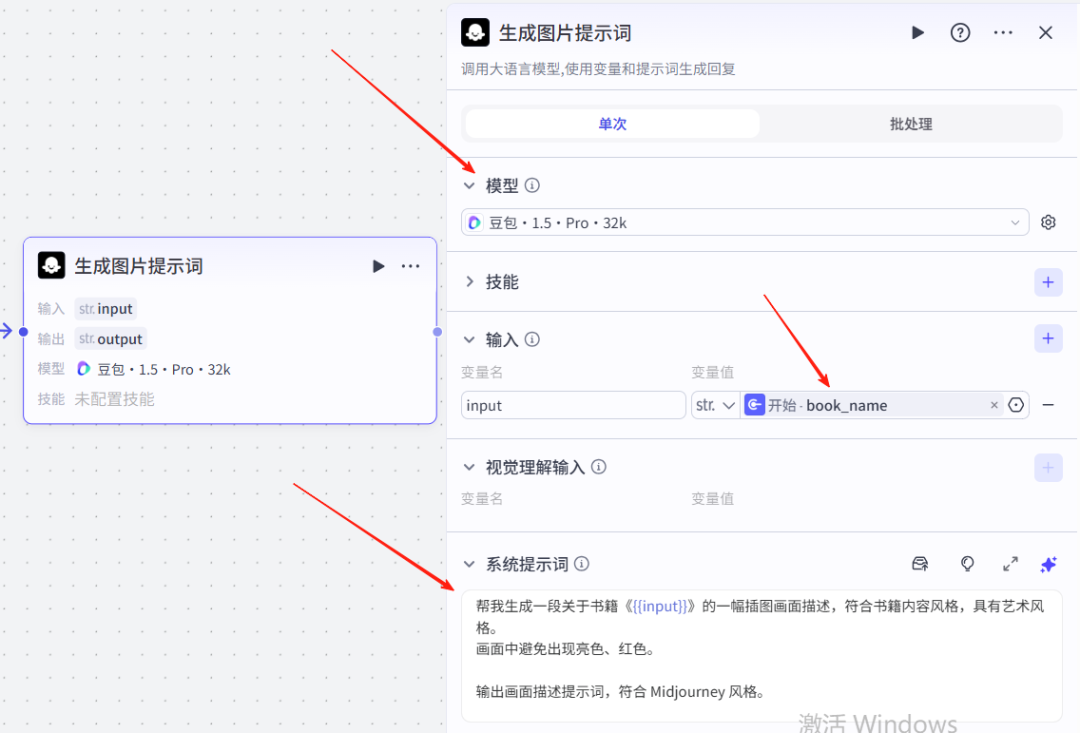
系统提示词,把这段提示词复制粘贴到里面:
帮我生成一段关于书籍《{{input}}》的一幅插图画面描述,符合书籍内容风格,具有艺术风格。画面中避免出现亮色、红色。输出画面描述提示词,符合 Midjourney 风格。
10、生成背景图-节点
在生成图片提示词的节点右侧点击+,然后我们选择图像生成
模型选择:通用-pro,比例选择:16:9,生成质量拉满
输入的变量值是生成图片提示词的output,变量名是prompt,正向提示词:{{prompt}}
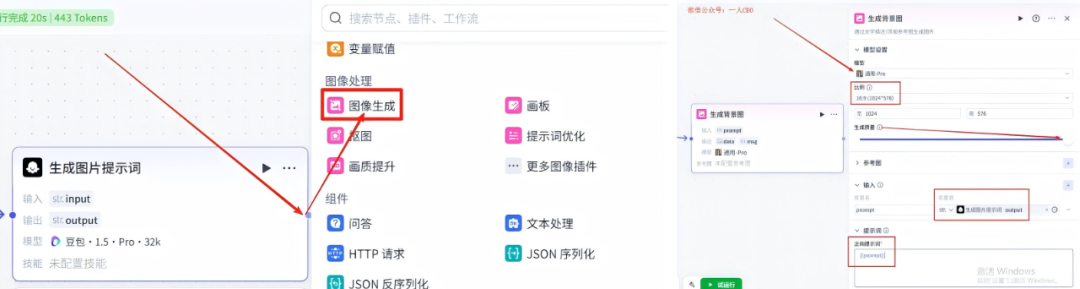
11、获取开场白时长-节点
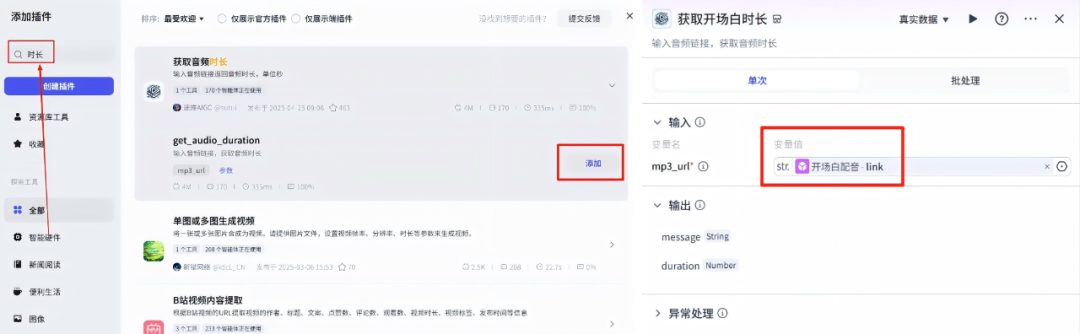
在生成背景图-节点的右侧点击+,然后选择插件,在搜索框输入:时长,在列表里面添加这个插件,节点配置信息,变量值是开场白配音的link变量
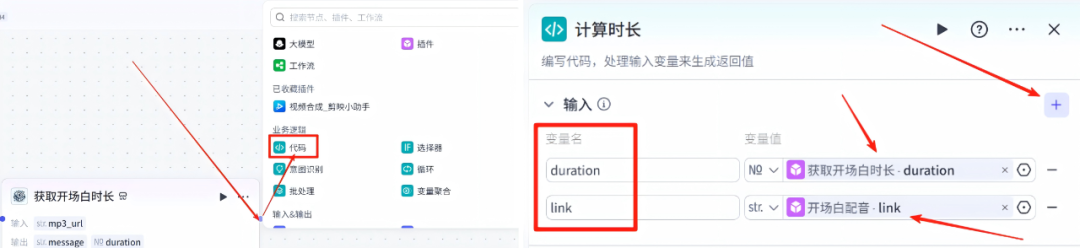
12、计算时长
在开场白时长的节点右侧点击+,然后选择 代码
输入项的配置信息,添加两个变量,duration的变量值是获取开场白时长的duration的变量,link的变量值是开场白配音的link变量
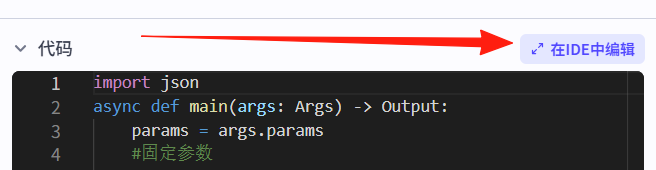
代码配置,这里重点讲一下,点击 在IDE中编辑,然后我们把语言改为:Python,然后把自带的代码删除掉,然后把如下代码复制粘贴进去
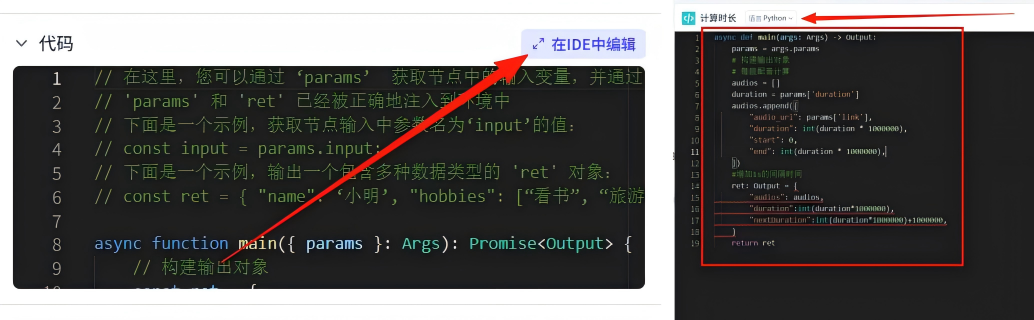
async def main(args: Args) -> Output:params = args.paramsaudios = []duration = params['duration']audios.append({"audio_url": params['link'],"duration": int(duration * 1000000),"start": 0,"end": int(duration * 1000000),})ret: Output = {"audios": audios,"duration":int(duration*1000000),"nextDuration":int(duration*1000000)+1000000,}return ret
输出项的配置如下图所示:
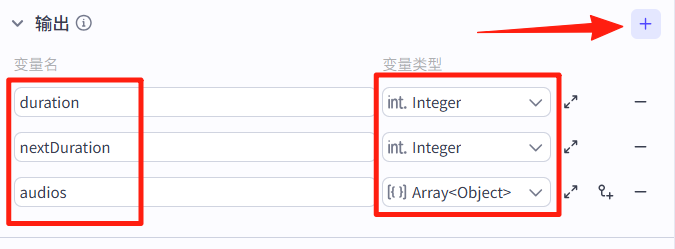
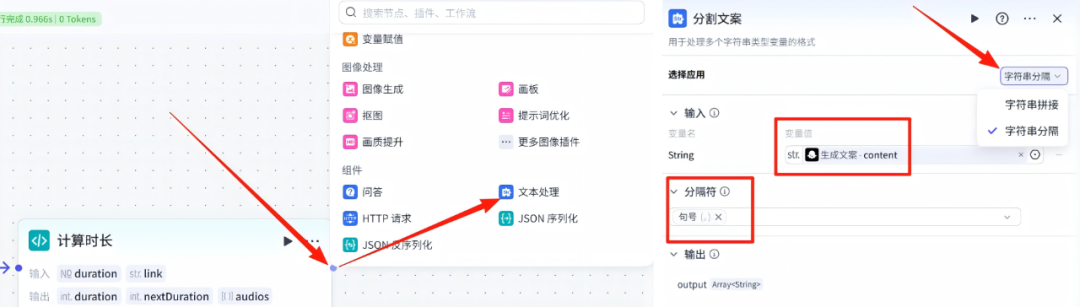
13、分割文案-节点
在计算时长节点的右侧点击+,然后选择 文本处理
节点配置:选择应用我们要选择字符串分隔,输入项的变量值是生成文案节点的content变量,然后就是分隔符我们选择《句号》
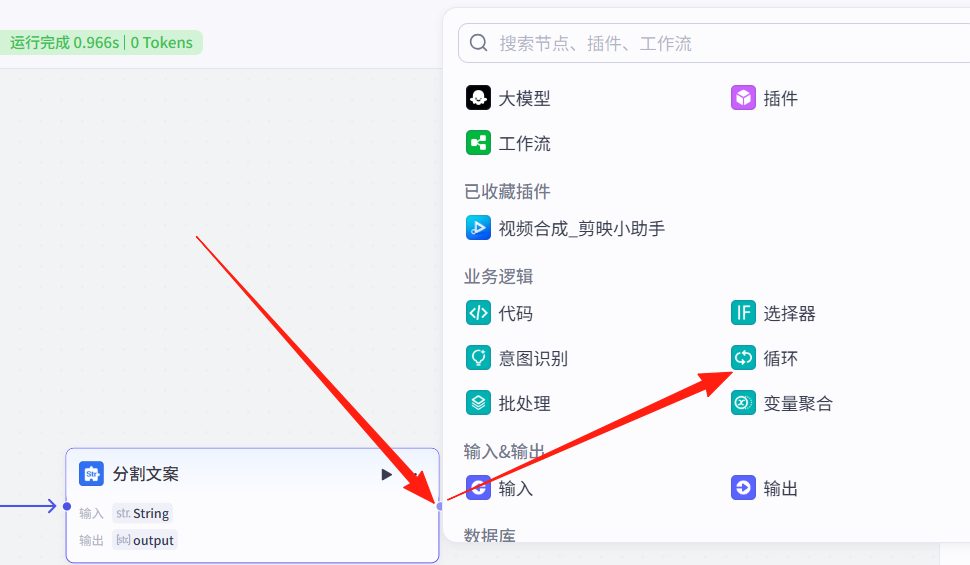
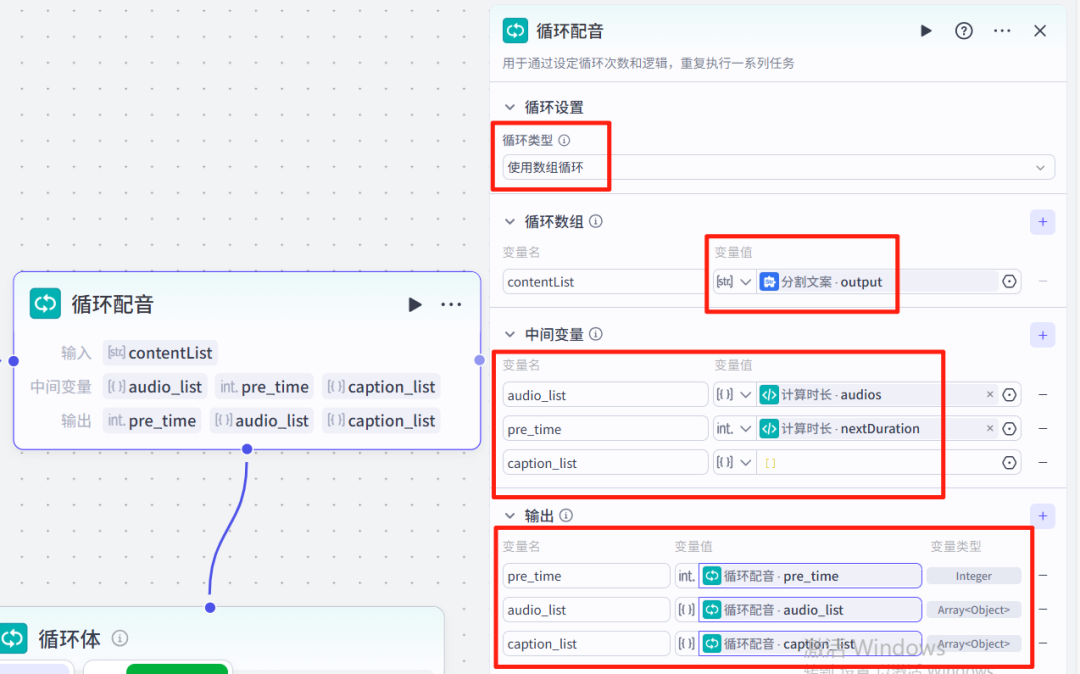
14、循环配音-节点
在分割文案节点的右侧点击+,然后选择 循环
这个节点很复杂,因为有循环和循环体,而且循环体包含了很多节点在里面,所以我们这里要用心一点,完整版的循环配音节点
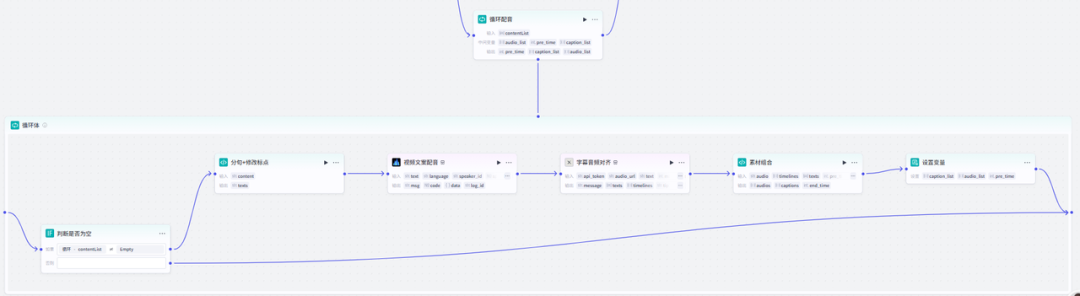
问题不大,我们一步步来配置然后也没什么难度,go跟上步骤!
循环配音节点的配置信息如下所示:
循环类型:使用数组循环,变量名 contentList的变量值是分割文案的变量output
中间变量的配置,audio_list对应的是计算时长audios,pre_time对应的是计算时长nextDuration,caption_list对应的是Array数组的Object类型
输出配置,变量值是中间变量名,然后对应的变量也是一样
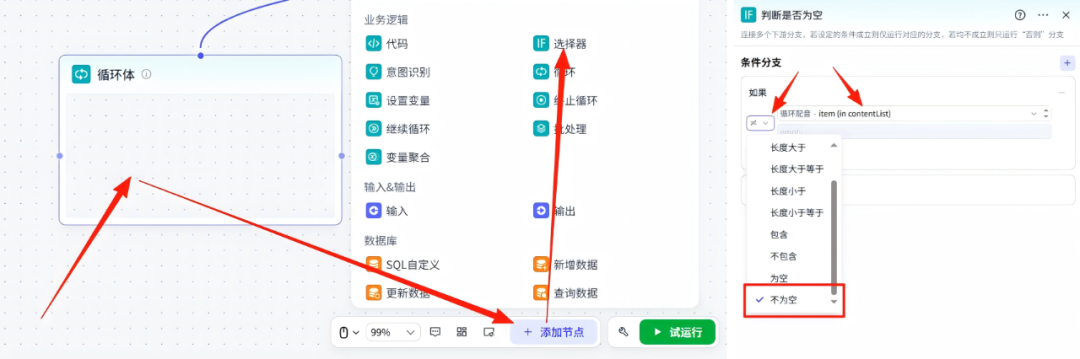
14-1、循环体配置-选择器节点
我们点击循环体的空白处,然后点击添加节点,点击选择器,配置信息:在如果条件分支里面选择循环配音item,然后条件-不为空
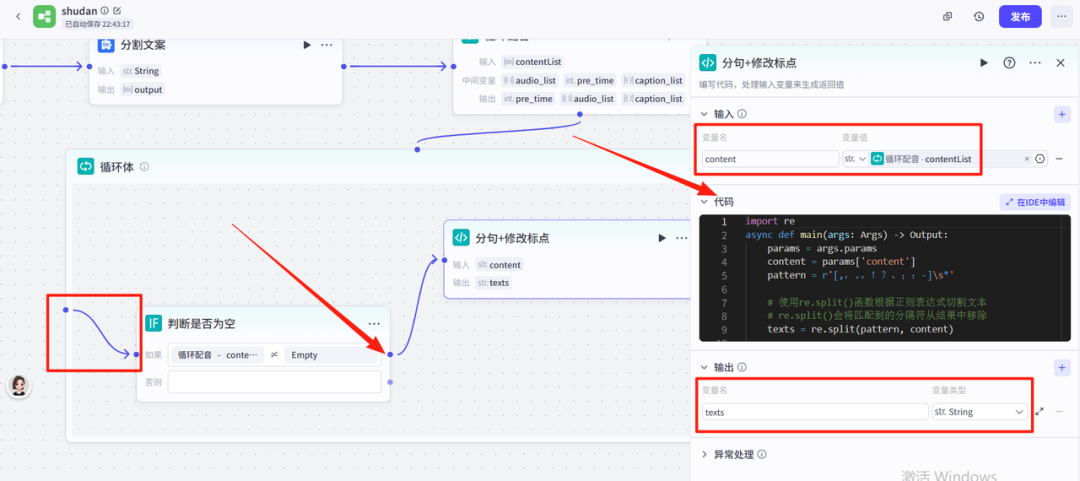
14-2、循环体配置-分句+修改标点 节点
把判断是否为空的节点和循环体对接起来,然后在如果--右侧点击+,添加代码节点,这个节点的主要作用是把文案进行分句,为了后面视频的朗读,输入项的变量值是循环配音节点的contentList变量,输出 变量名texts变量值为String
代码步骤:改为python语言,然后把下面代码复制粘贴进去
import reasync def main(args: Args) -> Output:params = args.paramscontent = params['content']pattern = r'[,,.。!?、;:-]s*'# 使用re.split()函数根据正则表达式切割文本# re.split()会将匹配到的分隔符从结果中移除texts = re.split(pattern, content)# 移除数组中可能存在的空字符串元素texts = [t for t in texts if t]# 处理文本片段:# 1. 去除所有英文/中文的单引号或者双引号# 2. 将——改为中文逗号processed_texts = []for text in texts:# 去除英文/中文的单引号或者双引号text = re.sub(r'['"""]', '', text)# 将——改为中文逗号text = text.replace('——', ',')processed_texts.append(text)# 构建输出对象ret: Output = {"texts": "n".join(processed_texts)}return ret
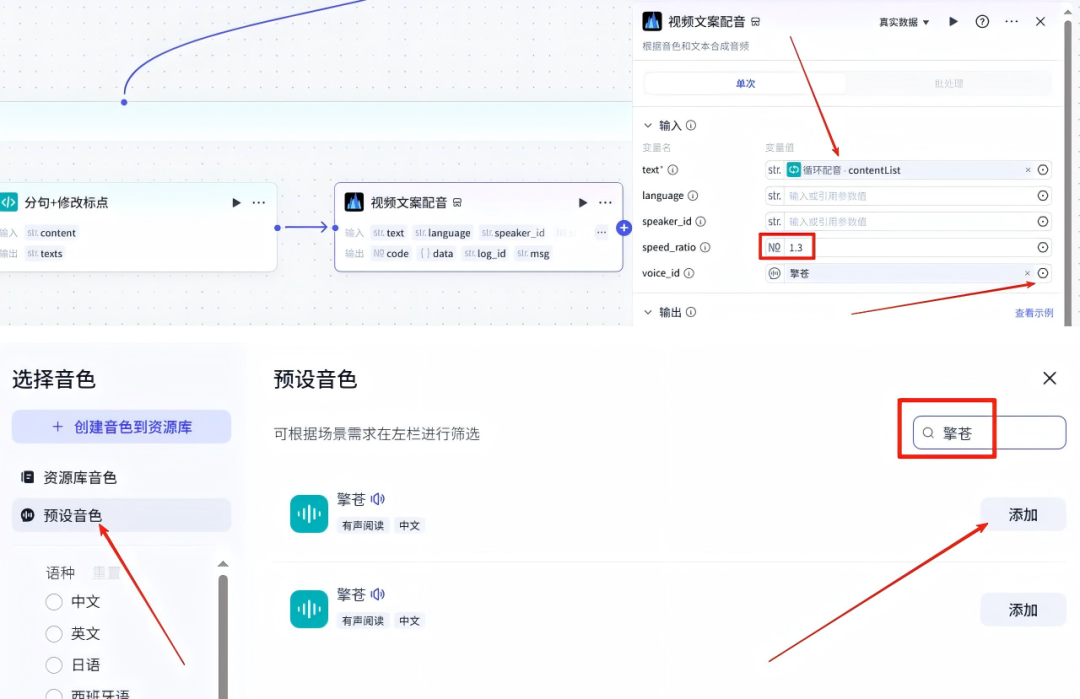
14-3、循环体配置-视频文案配音-节点
在分句+修改标点的节点右侧点击+,然后选择-插件,在搜索框输入:语音合成,我们点击-添加,节点配置如下:
text:选择循环配音的contentList
speed_ratio:1.3
voice_id:朗读声音我们选择--擎苍
14-4、循环体配置-字幕音频对齐-节点
在视频文案配音-节点的右侧点击+,然后点击插件,在搜索框输入:字幕音频对齐,点击添加,节点配置如下:对着操作就行了
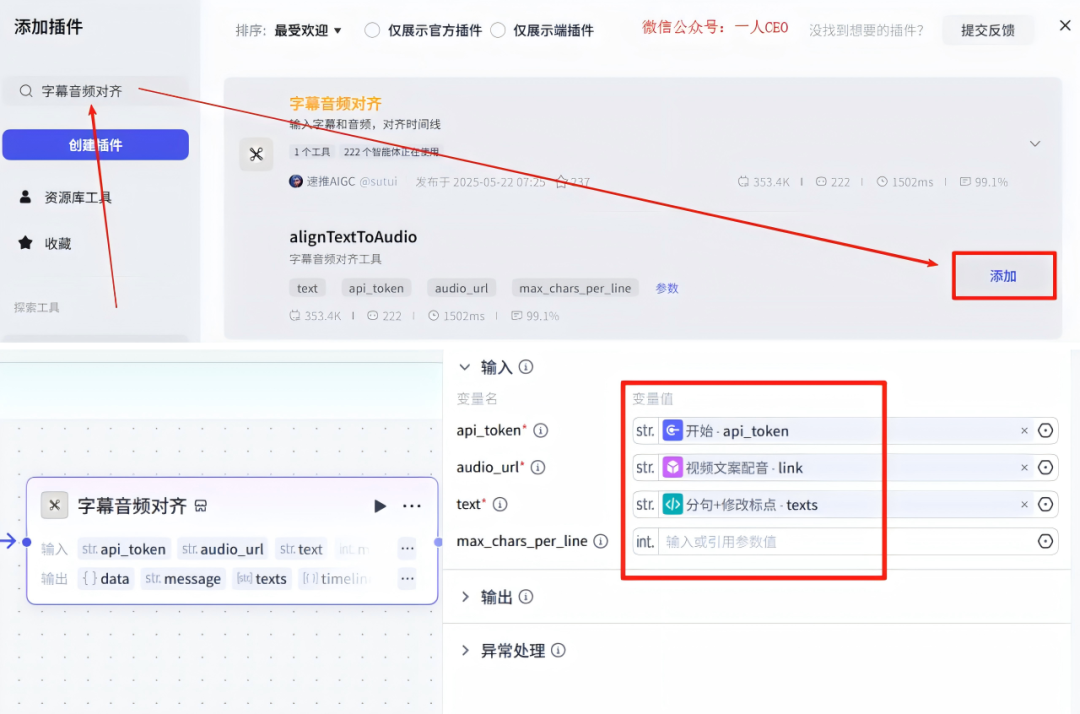
14-5、循环体:素材组合-节点
在字幕音频对齐的右侧点击+,点击-代码节点,然后重命名为:素材组合
输入项的变量名和变量值伙伴们自己对着操作就行了,这就是为什么我一开始叫你们把每一个节点都重新重命名的原因,就是为了后续方便我们操作
代码配置,点击在IDE中编辑,然后把语言改为Python,然后把下面的代码复制粘贴进去即可
输出项的变量名和变量值,伙伴们自己对着操作哈
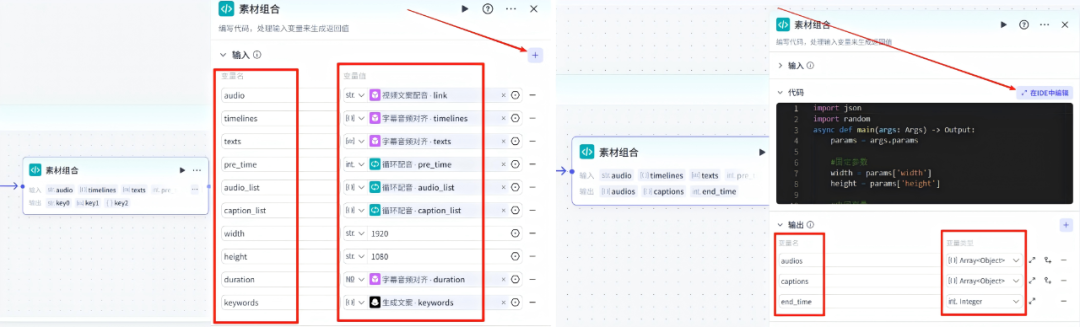
import jsonimport randomasync def main(args: Args) -> Output:params = args.paramswidth = params['width']height = params['height']captions = params['caption_list']audios = params['audio_list']timelines = params['timelines']audio = params['audio']texts = params['texts']duration = params['duration']pre_time = params['pre_time']keywords = params.get('keywords', [])audios.append({"audio_url": audio,"duration": int(duration * 1000000),"start": pre_time,"end": pre_time+int(duration * 1000000),})for index2 , obj in enumerate(timelines):caption = {'text': texts[index2],'start': int(pre_time + obj['start']),'end': int(pre_time + obj['end']),"in_animation":"渐显","out_animation":"渐隐"}for kw_obj in keywords:kw = kw_obj.get('kw', '')if kw and kw in texts[index2]:caption['keyword'] = kwcaption['keyword_color'] = '#fe8a80'breakcaptions.append(caption)ret = {"captions": captions,"audios": audios,"end_time":pre_time+int(duration * 1000000)}return ret
14-6、循环体:设置变量
在素材组合节点的右侧点击+,然后选择--设置变量节点
该节点配置如下:循环配音的中间变量对应素材组合的变量,然后这个节点是最后一个节点,我们就把这个节点和循环体对接起来
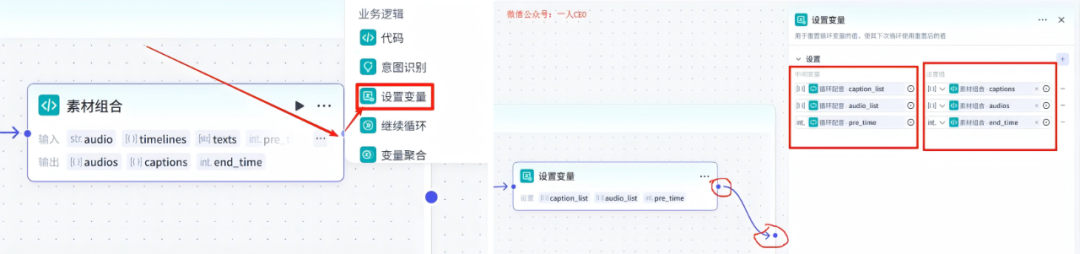
然后把判断是否为空节点也和循环体结尾链接起来

15、结构组合-节点
在循环配音节点的右侧点击+,选择一个代码节点,重命名为结构组合
左侧图片是输入项配置,右侧图片是输出项配置
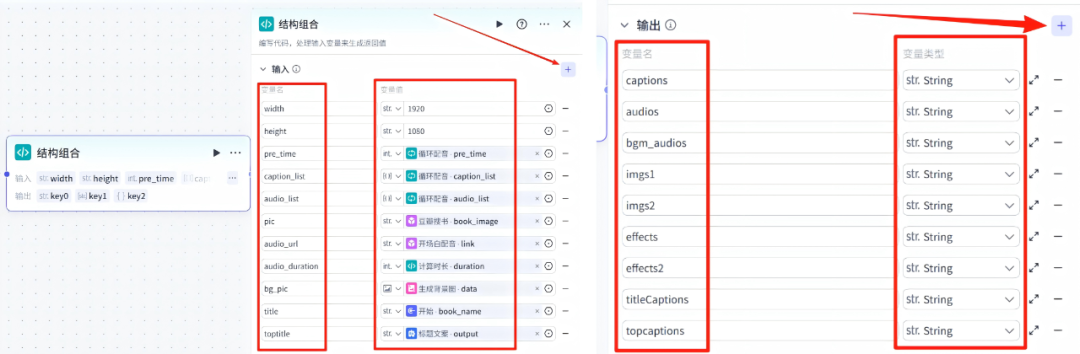
结构组合-代码配置:点击在IDE中编辑,把语言改为Python,然后把下面代码复制粘贴进去即可
import jsonasync def main(args: Args) -> Output:params = args.paramscover_image = params['pic']bg_image = params['bg_pic']audio_duration = params['audio_duration']toptitle = params['toptitle']width = params['width']height = params['height']pre_time = params['pre_time']imgs1 = []imgs2 = []title_captions = []bgm_audios = []title_captions.append({'text': params['title'],'start': audio_duration+1000000,'end': pre_time,"in_animation":"缩小","in_animation_duration":2000000})topcaptions = []topcaptions.append({'text': toptitle,'start': audio_duration+1000000,'end': pre_time,"in_animation":"渐显","in_animation_duration":1000000})audios = params['audio_list']bgm_audios.append({"audio_url": "https://houht.oss-cn-shanghai.aliyuncs.com/public/booklist/book.MP3","duration": 2000000,"start": 0,"end": 2000000})bgm_audios.append({"audio_url": "https://ve-template-0920.oss-cn-shanghai.aliyuncs.com/uploads/1747213706549_bzwh21eozgv.mp3","duration": pre_time-2000000,"start": 2000000,"end": pre_time,"volume":0.7})imgs1.append({"image_url": cover_image,"width": 768,"height": 1024,"start": 0,"end": audio_duration+1000000+500000,"transition":"中心切开","transition_duration":1000000})imgs2.append({"image_url": cover_image,"width": 768,"height": 1024,"start": 0,"end": audio_duration+1000000,"in_animation": "翻书","in_animation_duration": audio_duration,"transition":"中心切开","transition_duration":1000000})imgs2.append({"image_url": bg_image,"width": width,"height": height,"start": audio_duration+1000000,"end": pre_time})effects = []effects.append({"effect_title": "模糊","end": audio_duration+1000000,"start": 0})effects2 = []effects2.append({"effect_title": "星火","end": pre_time,"start": audio_duration+1000000})ret = {"captions": json.dumps(params['caption_list']),"audios": json.dumps(audios),"bgm_audios": json.dumps(bgm_audios),"imgs1": json.dumps(imgs1),"imgs2": json.dumps(imgs2),"effects":json.dumps(effects),"effects2":json.dumps(effects2),"titleCaptions":json.dumps(title_captions),"topcaptions":json.dumps(topcaptions)}return ret
16、创建剪映草稿
在结构组合节点右侧+,点击插件,在搜索框:视频合成,在列表中点击添加该组件,然后更改名为创建剪映草稿
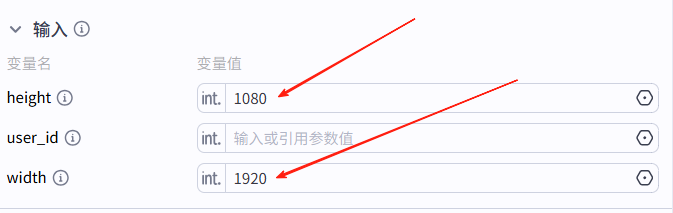
输入项配置:
17、背景音乐和文案配音
在创建剪映草稿节点后面添加两个:add_audios插件
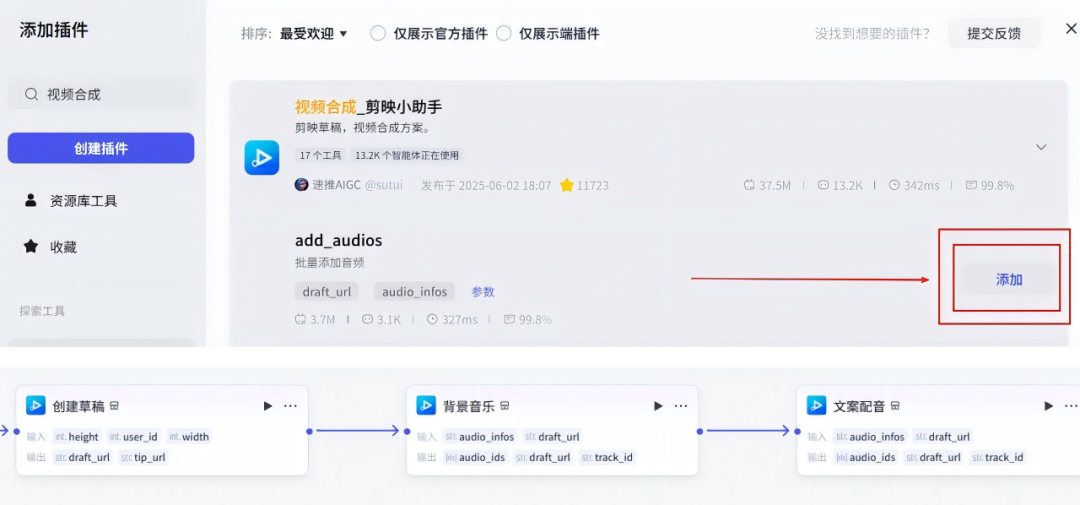
这两个节点的配置如下:
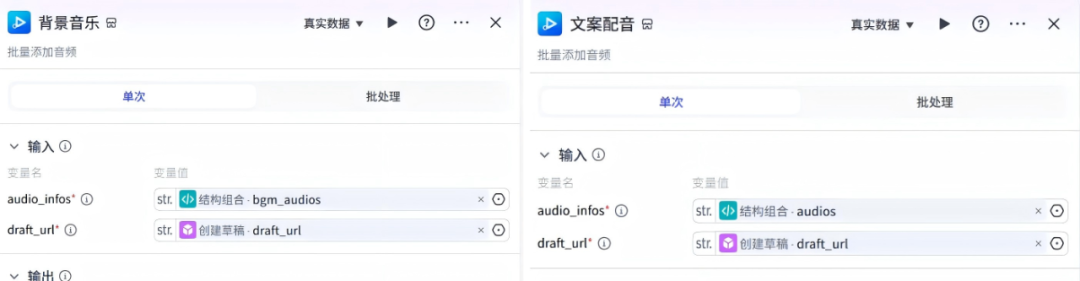
18、开场封面
在文案配音节点右侧+,点击插件,搜索视频合成,添加两个add_images插件
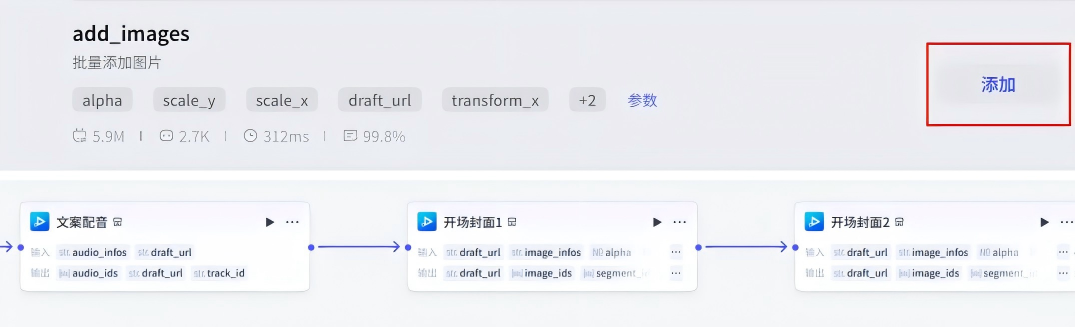
这两个节点配置信息如下:
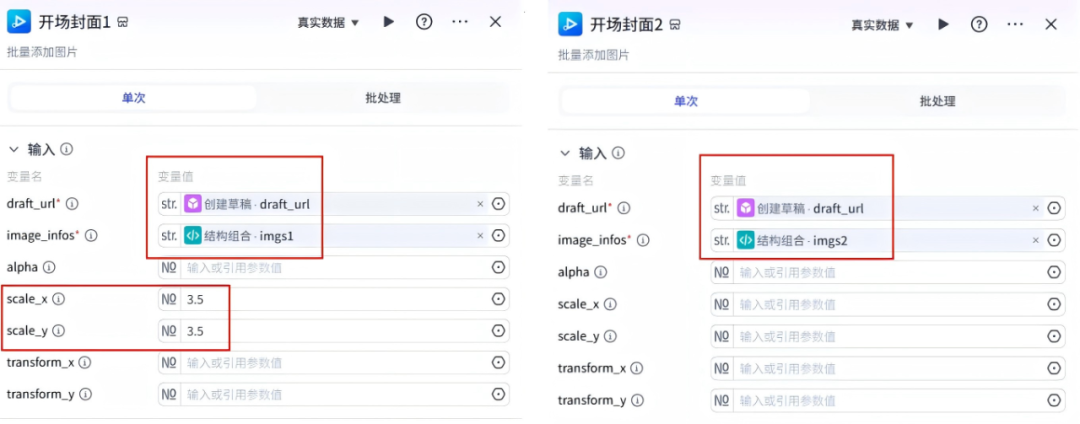
19、添加视频特效
在开场封面2节点右侧+,点击插件,搜索视频合成,添加两个add_effects插件
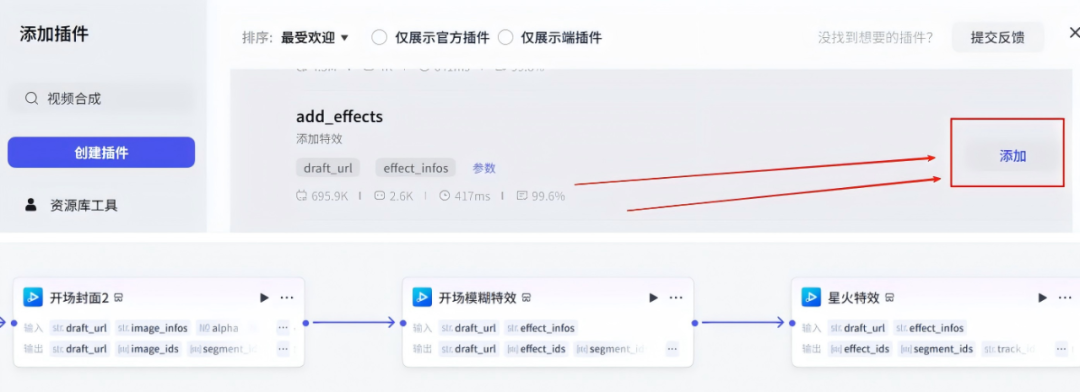
这两个节点的配置信息如下:
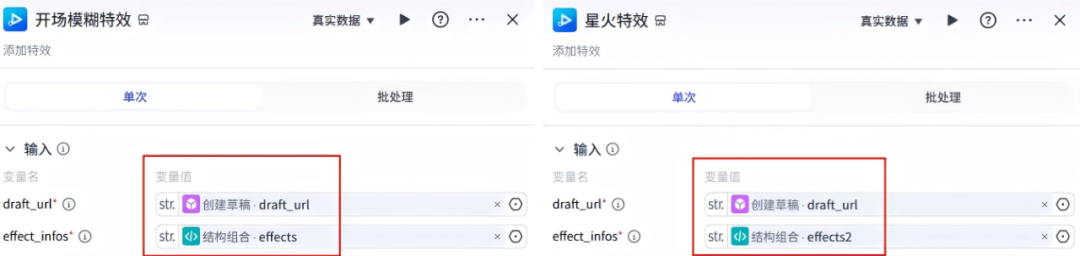
20、添加判断
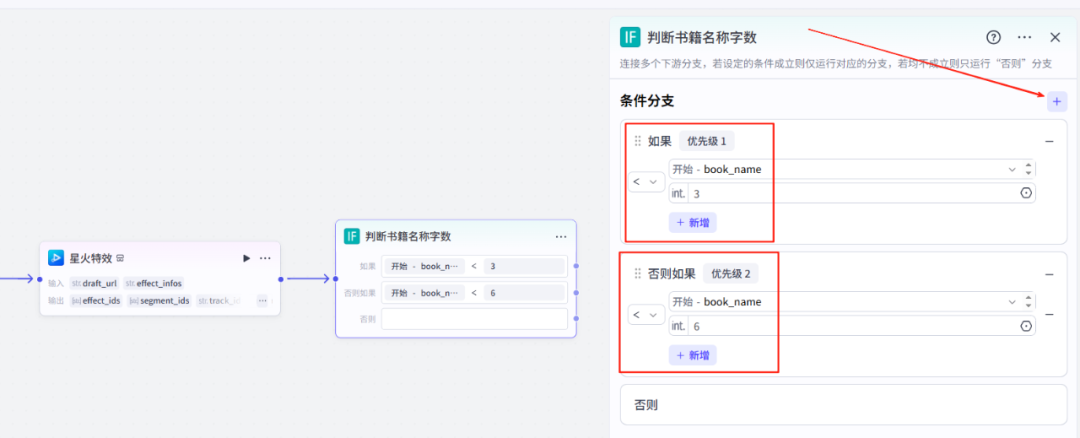
在星火特效节点右侧+,点击IF选择器,这个节点的作用是判断书籍名称的长度,然后选择走那个路径,配置信息如下:
开始节点-book_name,int 3,条件是 长度小于
开始节点-book_name,int 6,条件是 长度小于
解释一下:开始节点的变量值book_name长度小于3或6,就走对应的路线
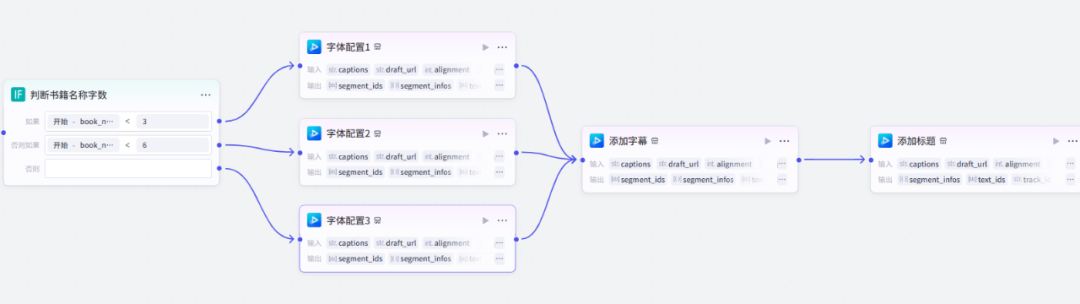
21、添加字幕
在IF选择器节点右侧+,点击插件,搜索视频合成,添加5个add_captions插件

路径排版如下:
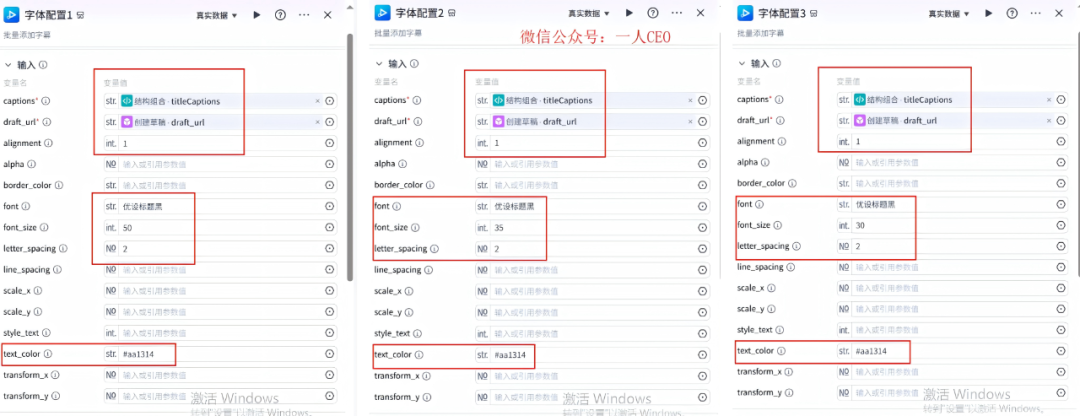
字体配置节点配置信息如下:
《添加字幕》节点配置和《添加标题》节点配置如下:
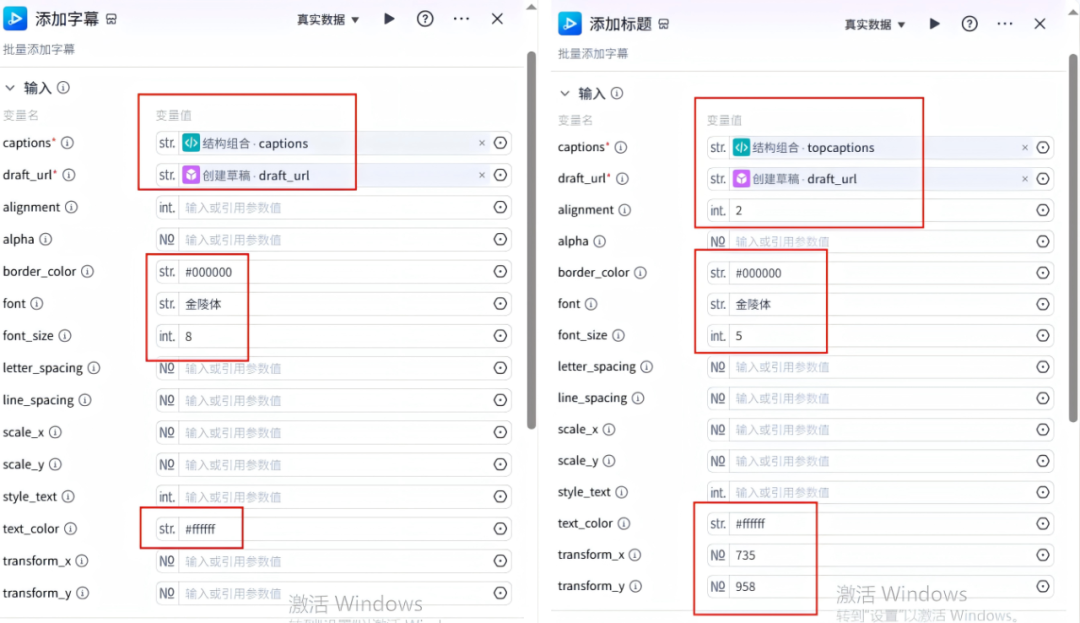
22、结束节点
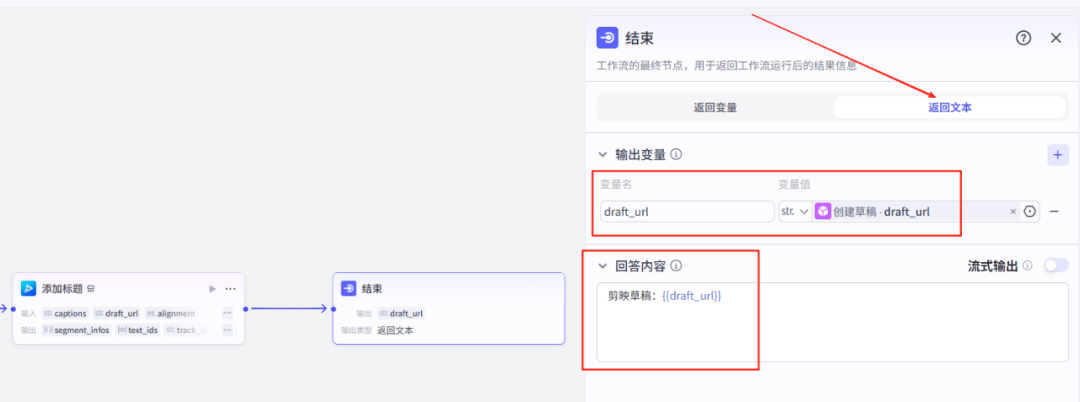
23、注册/登录
打开速推AIGC:https://ts.fyshark.com/#/login
使用手机《微信》扫码登录,点击个人中心,点击充钱,然后把API复制
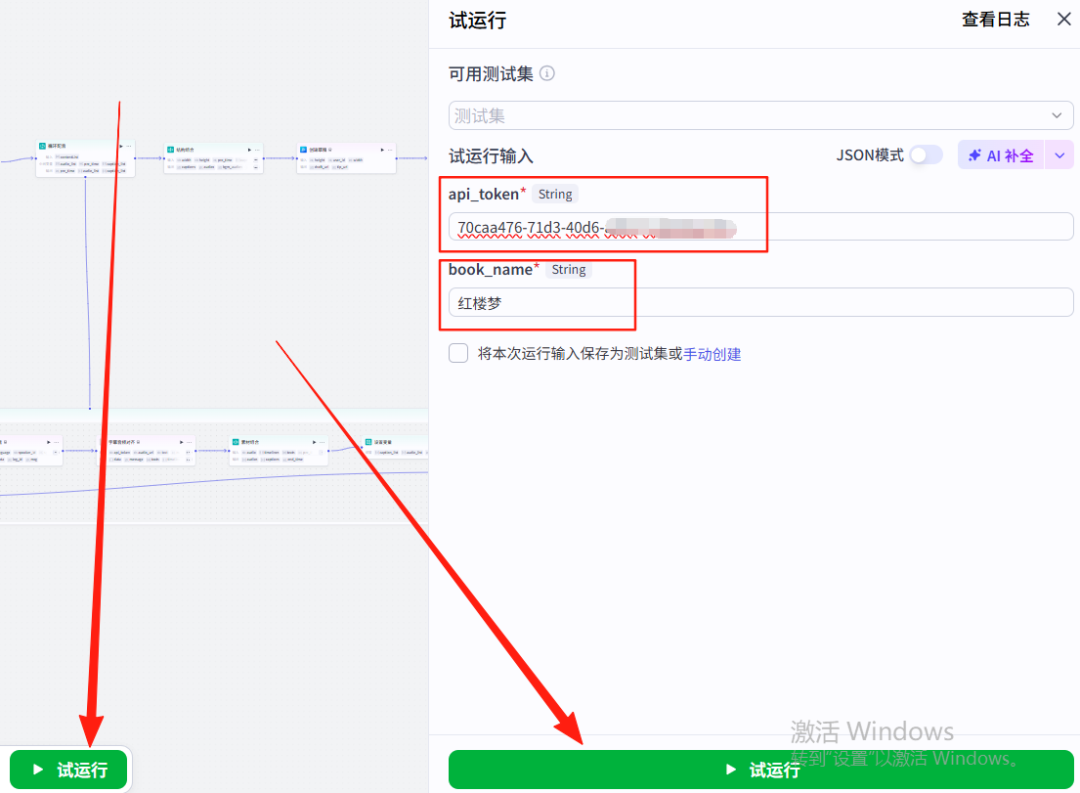
24、试运行
点击试运行按钮,弹出对话框,api_token就是我们刚刚复制上面网页的API,book_name就是你的书籍名称
获取视频草稿链接:

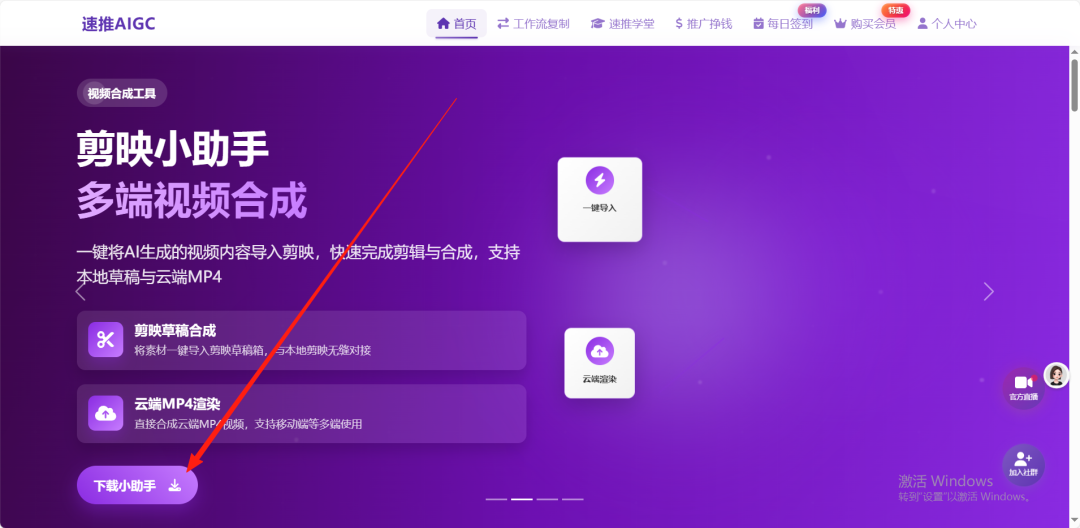
但是我们要下载这个视频草稿,还要去下载一个软件:剪映小助手
就是刚刚那个网站,点击首页,就可以看到下载啦
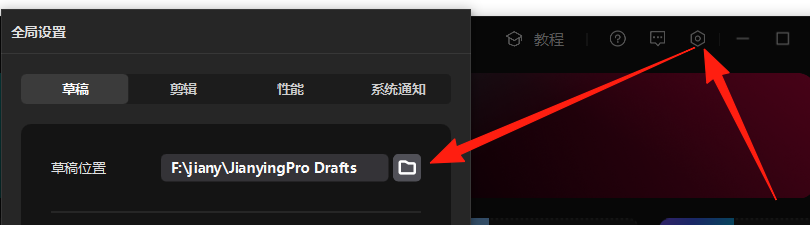
复制这个路径,切换到剪映小助手,点击设置路径,把剪映的草稿路径复制到里面。

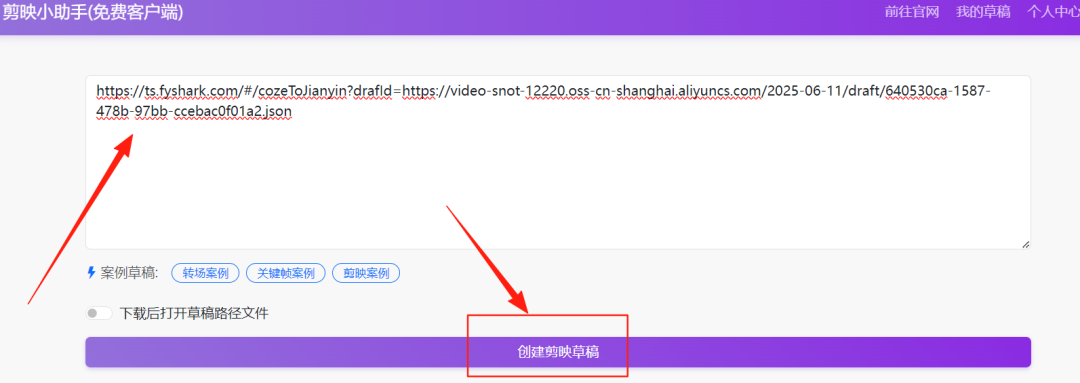
开始下载草稿,把刚刚在工作流输出结果的链接,复制粘贴到里面,然后点击创建剪映草稿,就下载到本地
然后我们打开剪映,就可以看到我们的草稿里面多出一个视频
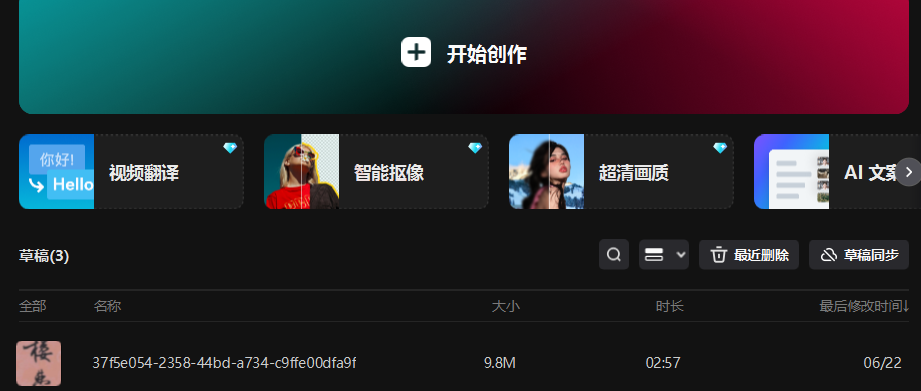
我们打开看看:完美生成成功!
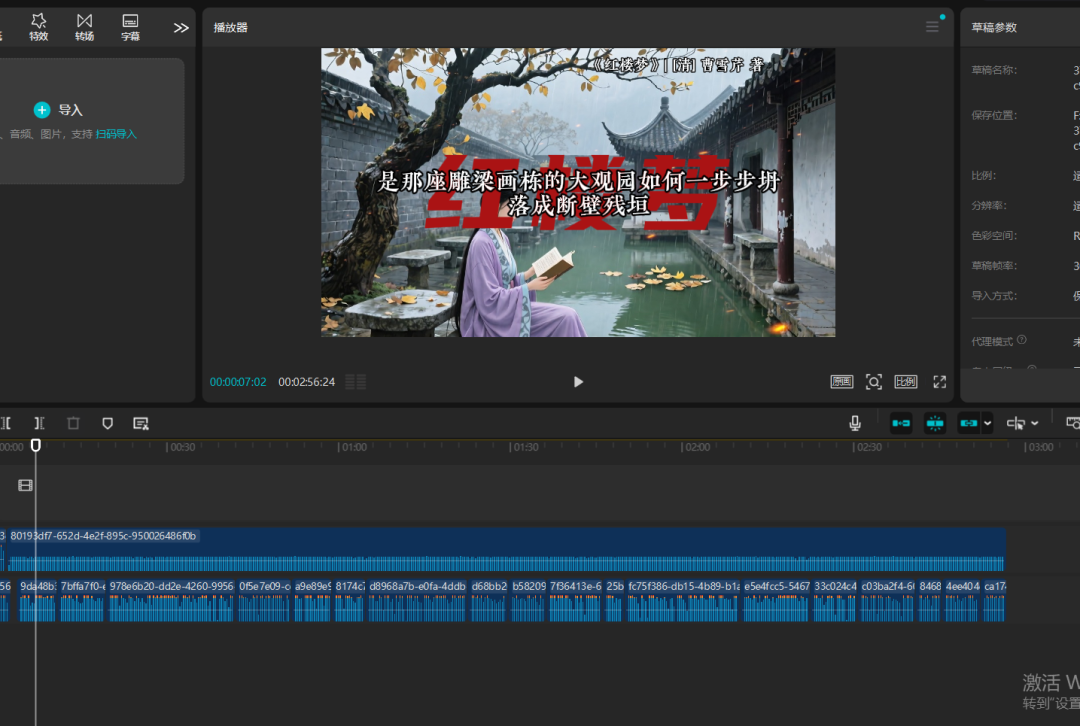
本次教程过于长篇,还请小伙伴们耐心看完,如果觉得对你有帮助,不妨动动手指转发给你身边的朋友,哈哈哈哈!
参考手册:生财有术
本篇文章来源于微信公众号: 一人CEO

文章评论