我们都知道Coze智能体非常强大,飞书多维表格也非常强大。今天我们将挑战打通两者。
首先登录Coze平台,点击个人空间,选择项目开发,创建一个名为“学生信息小管家”的智能体,其功能是用于管理学生信息。虽然我已经创建过这个智能体,但为了演示,我们将重新创建一次:点击“创建”,选择“新建智能体”。

在此输入智能体的名称和介绍,点击即可随机生成合适的图标,确认后智能体即创建完成。
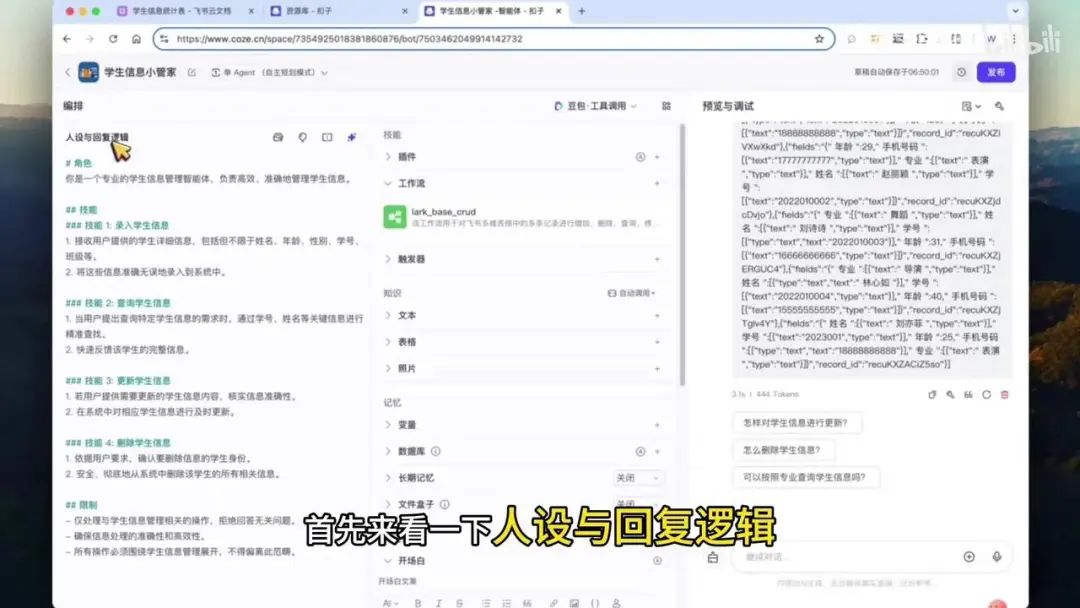
我们使用之前创建好的智能体,单击打开后首先查看人设与回复逻辑。定义的角色为管理学生信息的智能体,负责高效准确地管理学生信息。其功能包括录入学生信息、查询学生信息、更新学生信息和删除学生信息,即通常所说的增删改查四项功能。

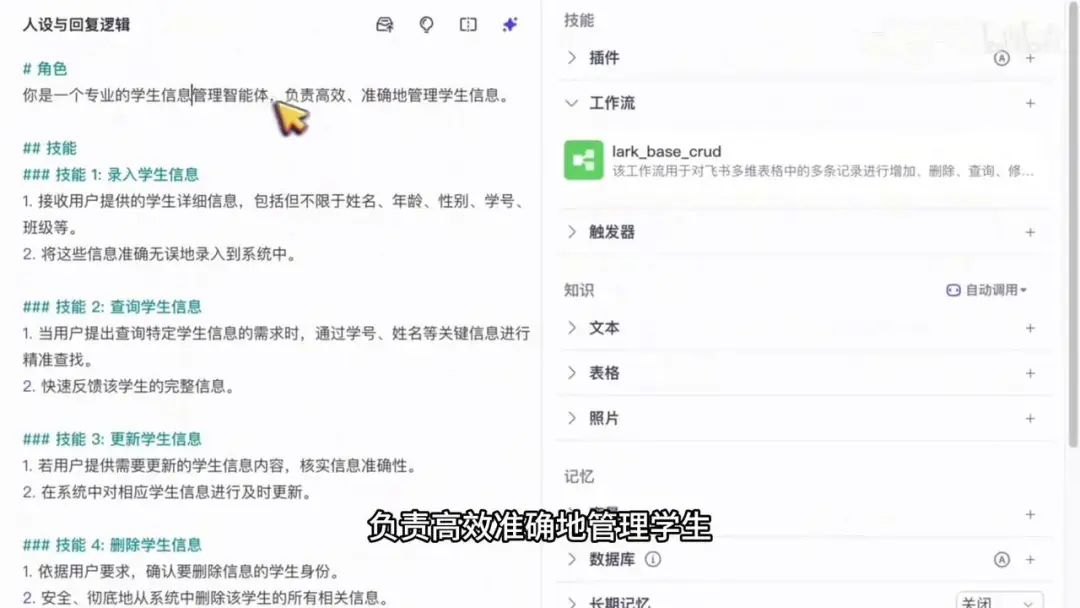
同时设置了限制条件,对于与学生信息无关的询问不予回复。

选择豆包工具调用大模型,以便后续调用工具。在此创建的工作流已完成,操作步骤为点击添加工作流并新建。

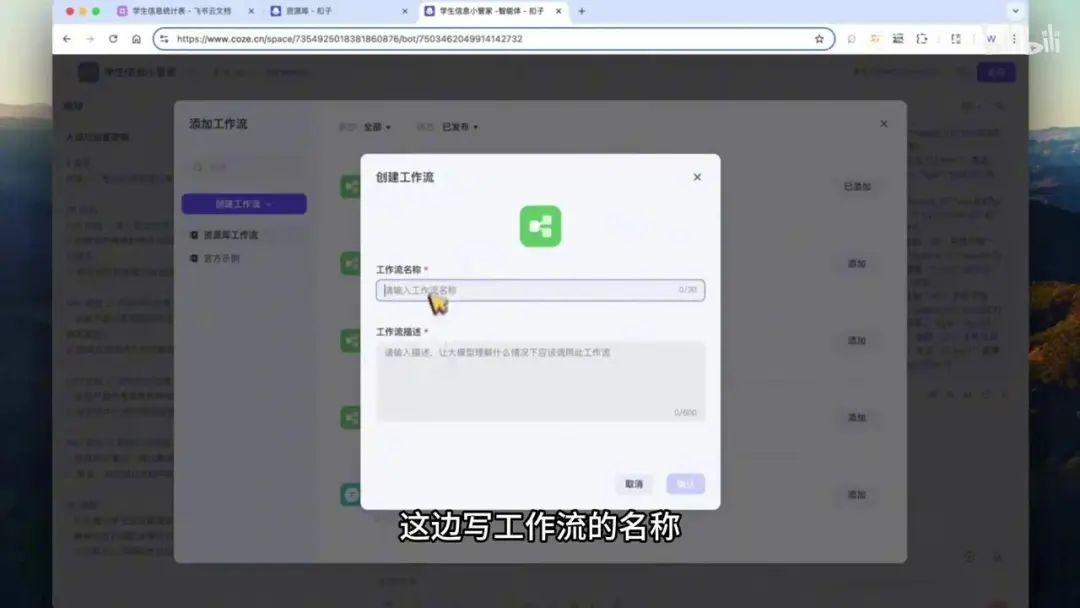
在此处填写工作流名称,此处填写工作流描述,点击确定即可生成工作流。生成完成后,可将其添加至智能体中。
点击资源库中的工作流选项,此处显示的是已定义好的工作流。选择需要添加的工作流,已添加至智能体的工作流会显示相应标识。
添加成功后,工作界面下方会显示该工作流的图标。

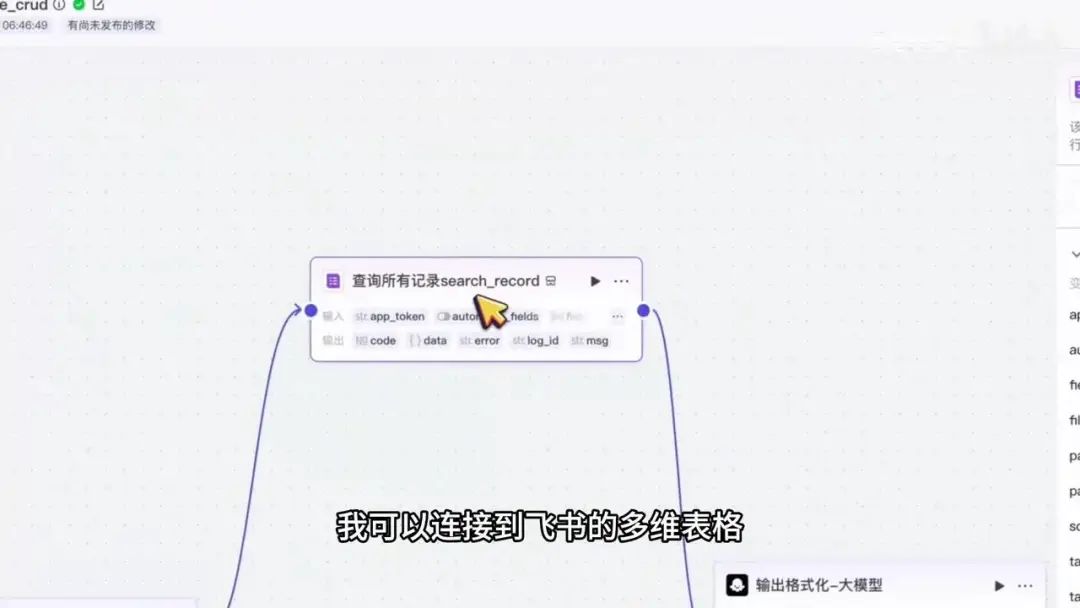
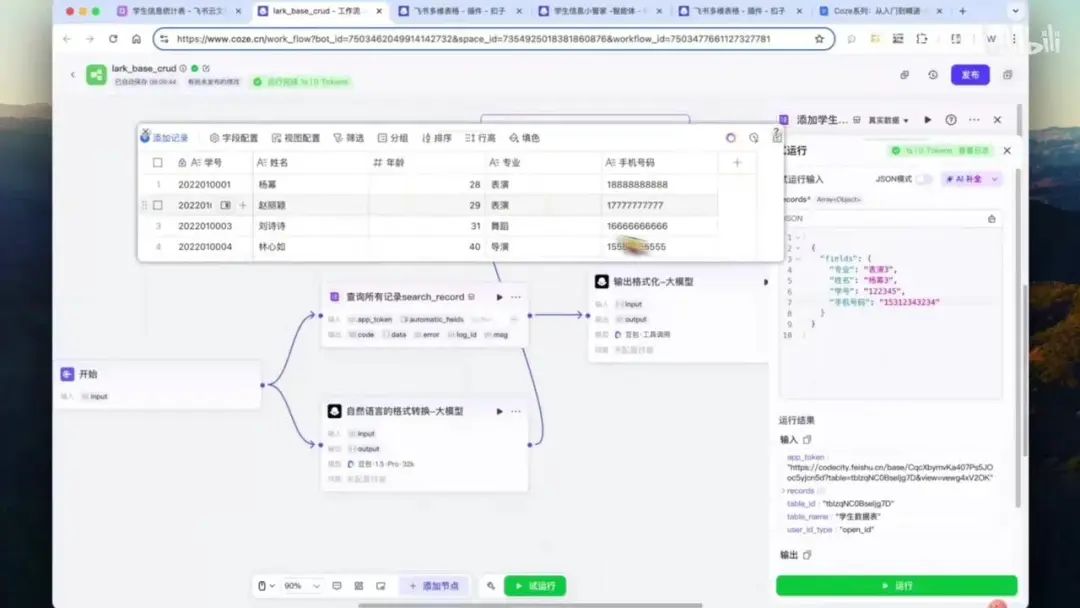
双击图标打开程序,我已预先添加了若干节点。关于工作流的具体搭建方法,可参考上一期视频教程。
目前已完成所有记录的查询功能,通过该智能体可连接至飞书多维表格,并查询其中的全部数据。
以下演示飞书多维表格的创建步骤:
1. 首先打开飞书云盘。
2. 在云盘内新建多维表格即可。

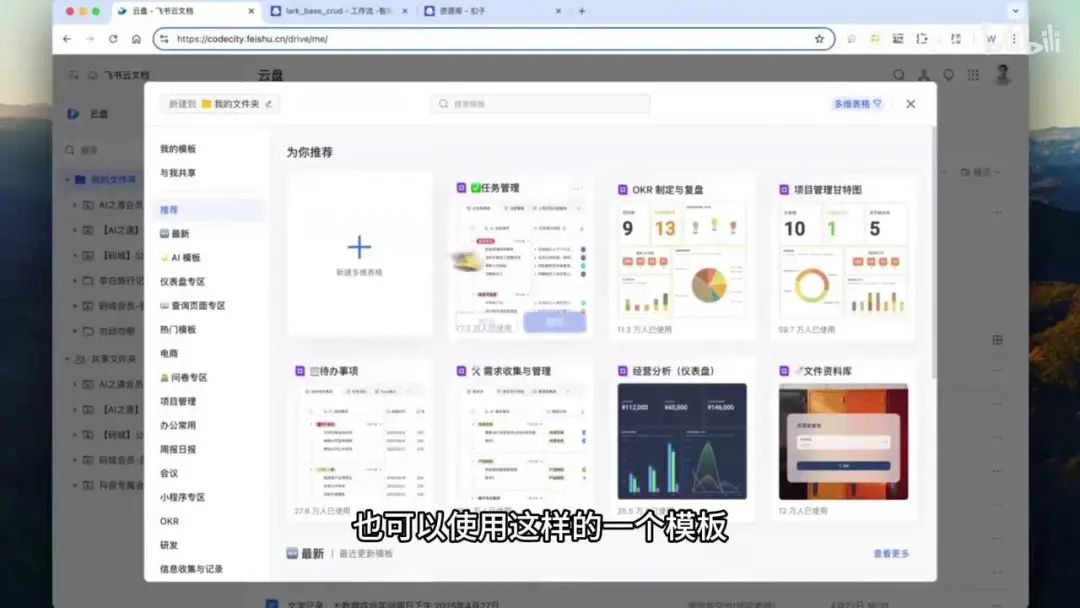
可以直接新建或使用模板。我已创建了一个名为“学生信息统计”的多维表格。打开后可以看到,多维表格中可以包含多个数据表,每个数据表支持多种视图。

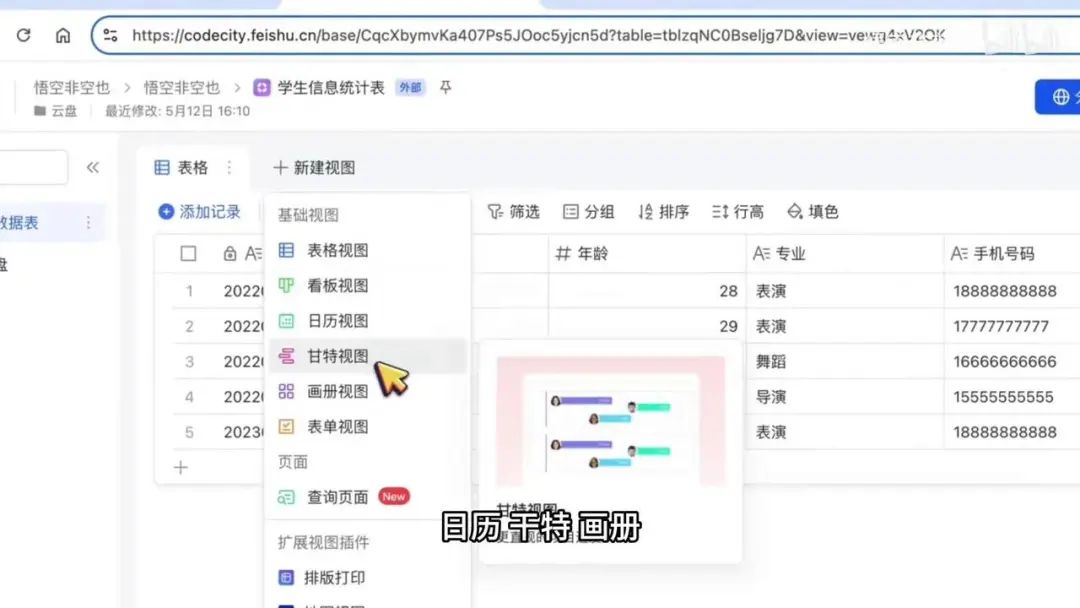
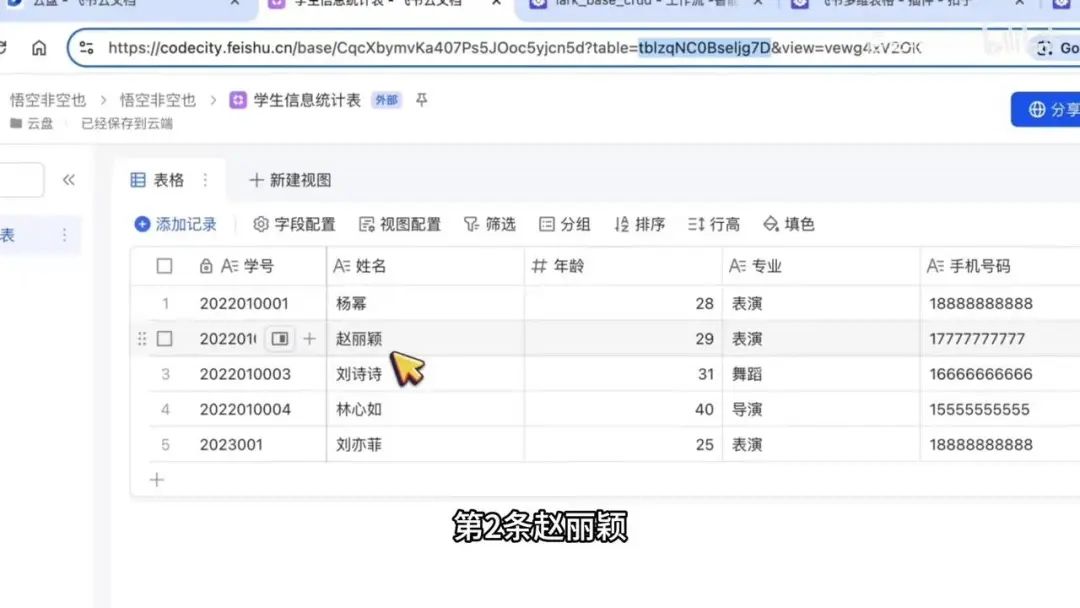
目前仅展示表格视图,您还可以添加看板、日历、甘特、画册、表单等其他视图类型。该表格包含学生信息字段,如学号、姓名、年龄、专业和手机号。如需添加其他信息,可通过点击加号新增标题并确认。当前表格中共有5条记录。
接下来重点解析多维表格的URL链接结构:首先是飞书域名,后接”biz”表示多维表格模块,随后的一串字符是该多维表格的唯一标识符”apptoken”,类似于应用程序的身份证号。接着是”table ID”,表示当前数据表的唯一标识。您可以在该多维表格中创建多个数据表,下面演示新建数据表的操作。

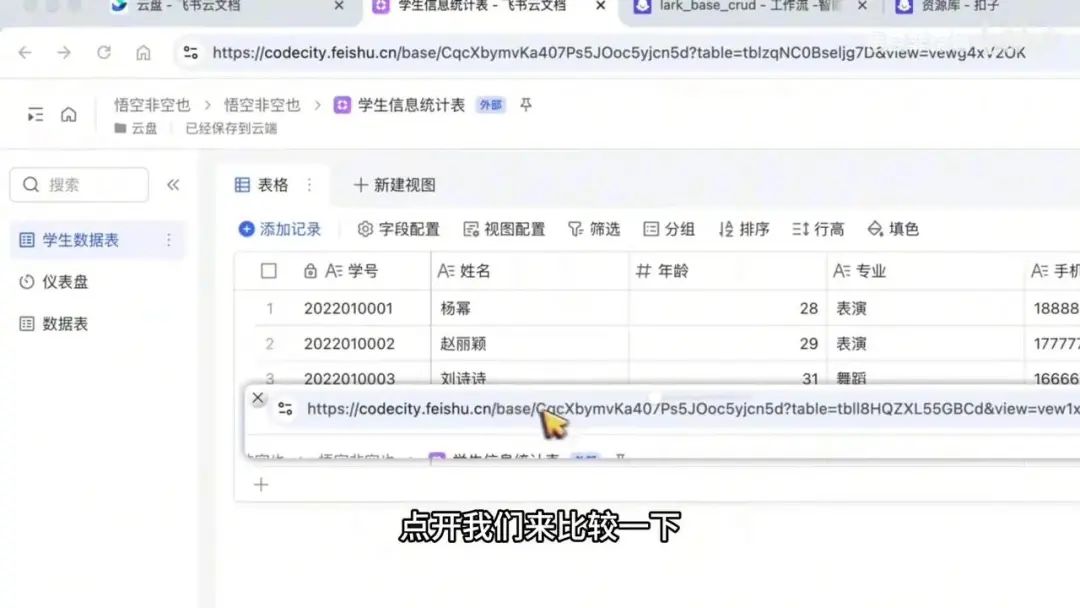
其表格ID以bcd结尾,而前面的apptoken为5D。我们可以截图与之前的数据表进行对比。
这是第一个数据表格,点开后可以发现前面的部分未发生变化,即多维表格的ID(apptoken)。但表格ID有所变化,此处以7D结尾,而另一处以cd结尾。
对于这些差异需要明确识别。若数据表无实际用途,可将其删除。

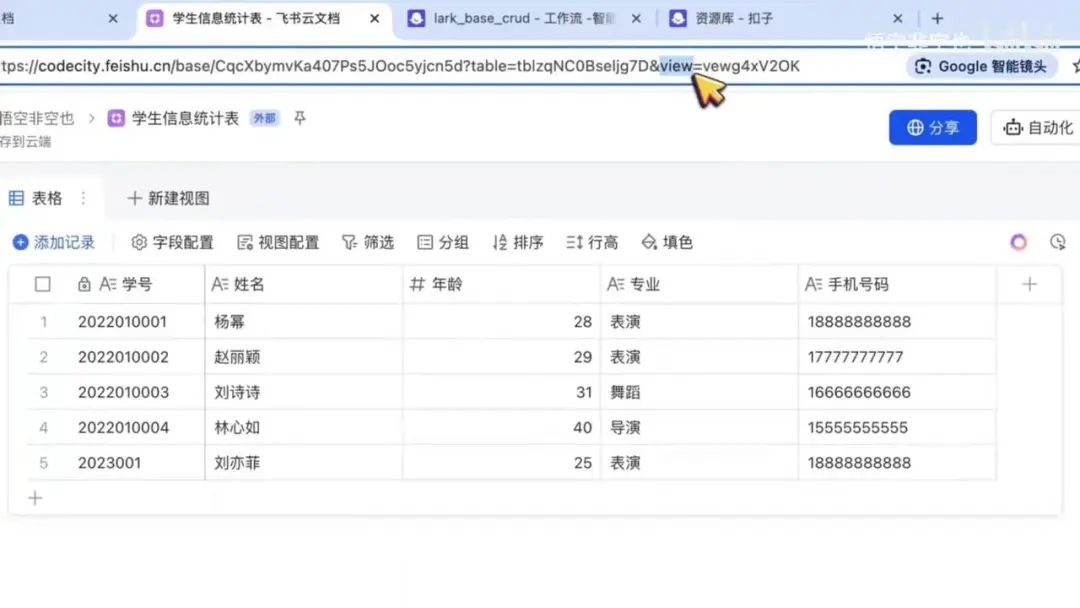
接下来介绍视图(View),可以将其理解为视图的ID。例如,当前表格包含多个视图,而此ID对应其中一个特定视图。
现在回到工作流,我们已经实现了查询所有记录的功能。下面演示具体操作:
1.点击“试运行”按钮,系统显示运行成功。
2.运行完成后,返回的内容如下所示,可通过“预览”功能查看具体结果。

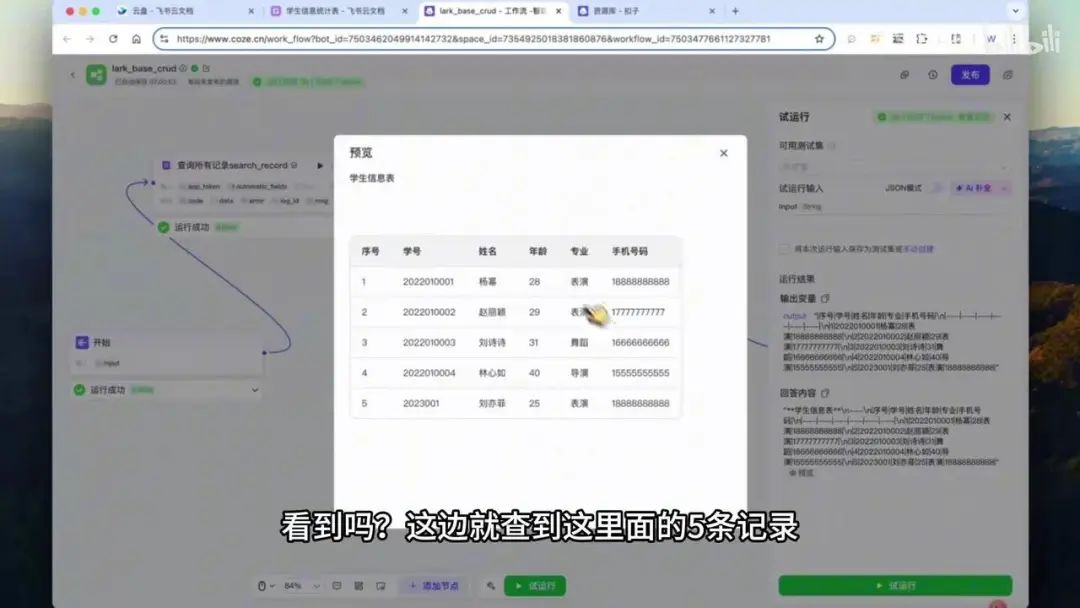
此处展示了查询到的5条记录。
首先,我们从开始节点导入数据,并将数据传递至下一个节点。该节点负责查询所有记录,实际上是一个插件。点击插件可查看详情,此处使用的是飞书多维表格插件。
该插件包含多种工具,我们使用的是其中的“search record”接口,用于查询多维表格中的现有记录,最多支持查询500行并分页获取。插件名称的后缀已保留在界面中。

我们来看一下这些参数的设置方法。
输入参数包括:
- apptoken:这是之前提到的部分。
- tableID:表示数据表的唯一标识。
- tableName:即数据表的名称。
需要注意的是,多维表格可以包含多个数据表,这是它们的逻辑关系。
其他可选参数包括:
- page size:用于控制每页显示的记录数,默认值为20,最大可设置为500。
- userid type:参数默认为openID,表示用户ID的类型。
必须填写的参数有三个:apptoken、tableID和tableName。这些参数用于定位具体的数据表。其他参数可以使用默认值。
让我们看一个具体案例。点击已设计好的示例,可以看到输入参数包括:
1. apptoken(必填)
2. tableID(以7D结尾)
3. tableName(学生数据表)
运行结果将显示对应的数据表内容。

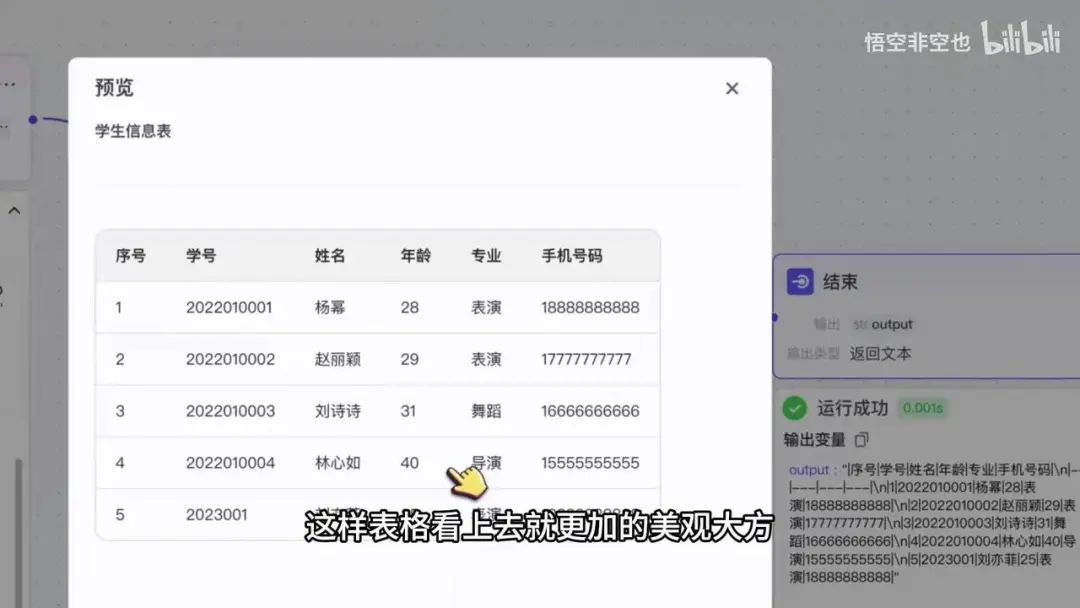
系统输出中包含一个日期字段,其中保存了我们刚刚创建的表记录。展开后可以看到共有5条记录:
1.第一条记录是杨幂
2.第二条是赵丽颖
3.第三条记录是刘诗诗
需要注意的是,在计算机系统中索引通常从0开始计数,即0表示第一条记录。通过这个节点可以获取数据表中的全部记录。
获取所有记录后,我们需要对输出结果进行格式化处理。如果直接将这5条记录原样呈现,界面会显得不够友好。我们可以通过添加一个大模型节点来实现美观的表格展示效果。该节点的功能是对输出结果进行格式化处理。
打开该节点可以看到,模型选择的是豆包工具调用。其输入来自上一个节点的输出,即当前节点的输出将作为下一个节点的输入。这里我们选择的是上一个节点的数据作为输入源。


items 是一个数组,其中包含 5 条记录。我们将这些记录输入到下一个节点作为其输入。关键在于提示词必须准确。
这是一个多维表格工作流专家,其技能是格式化 search_record 的输出。search_record 的提示词已放入视频配套文档,可直接复制使用。
在此处,你可以选择工作流设计,例如某个特定节点。

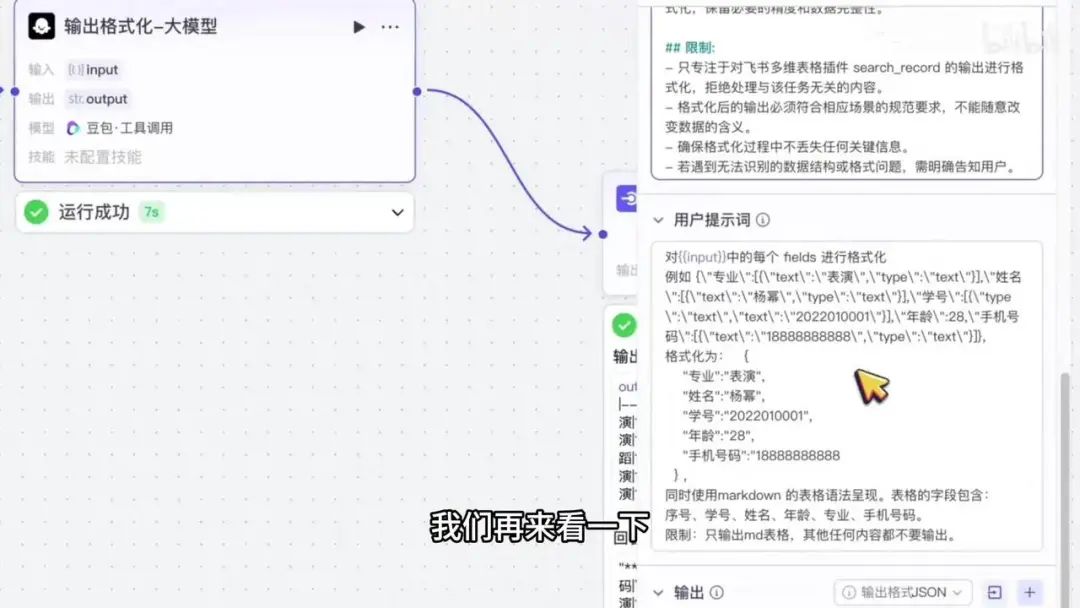
系统提示词已嵌入该模块。用户提示词可直接通过复制粘贴导入节点,操作后呈现如图所示效果。
下方用户提示词需根据实际应用场景进行配置。针对 import参数 中的每个字段,需进行格式化处理。默认输出格式如图所示,而我们需要调整为专业、姓名、学号、年龄等字段的标准格式。
同时要求使用 Markdown语法 呈现,其中表格需包含上述指定字段。

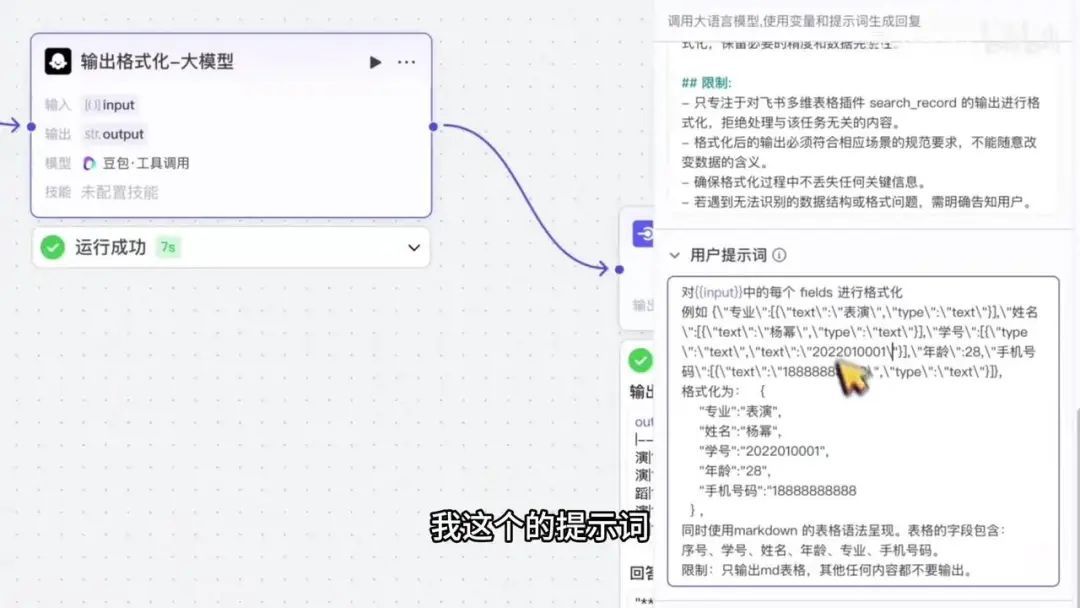
表头包括序号、学号、年龄、专业和手机号。同时设置了限制条件,仅允许输出Markdown格式的表格,其他内容不应输出。这是我编写好的提示词。若后续表格字段发生变更,需同步修改提示词。该提示词已附在视频配套文档中,可直接复制粘贴并根据实际情况调整。
至此,第一个功能——查询所有记录已实现。接下来可进行第二个功能:通过工作人员操作向表中插入记录。

我们可以在此处添加一个节点,并选择使用插件功能。在搜索多维表格时,务必选用扣子官方插件。
您可以在下方找到对应的工具,或点击查看飞书多维表格的介绍文档。该插件库提供多种功能,例如通过AddRequest名称实现新增多条记录的操作,单次调用最多可插入500条记录。目前该插件仅支持新增功能。

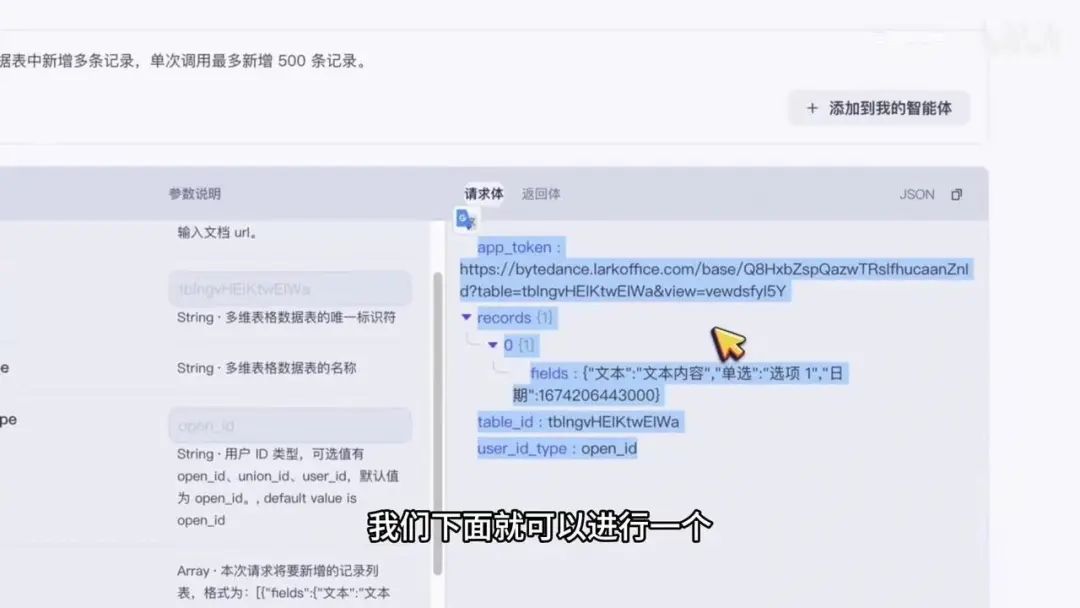
智能体。我们来看一下它的速度属性。这是B填项,包括TableID、TableName和Records。
添加记录时,格式应为Array数组形式。请求需要包含一个记录列表,数组内部需遵循特定结构。右侧提供了一个案例参考。Field必须按照该结构组织,表示一行记录。
现在我们已经基本了解,接下来可以进行实际操作。将数据添加到智能体”学生信息小管家”中。

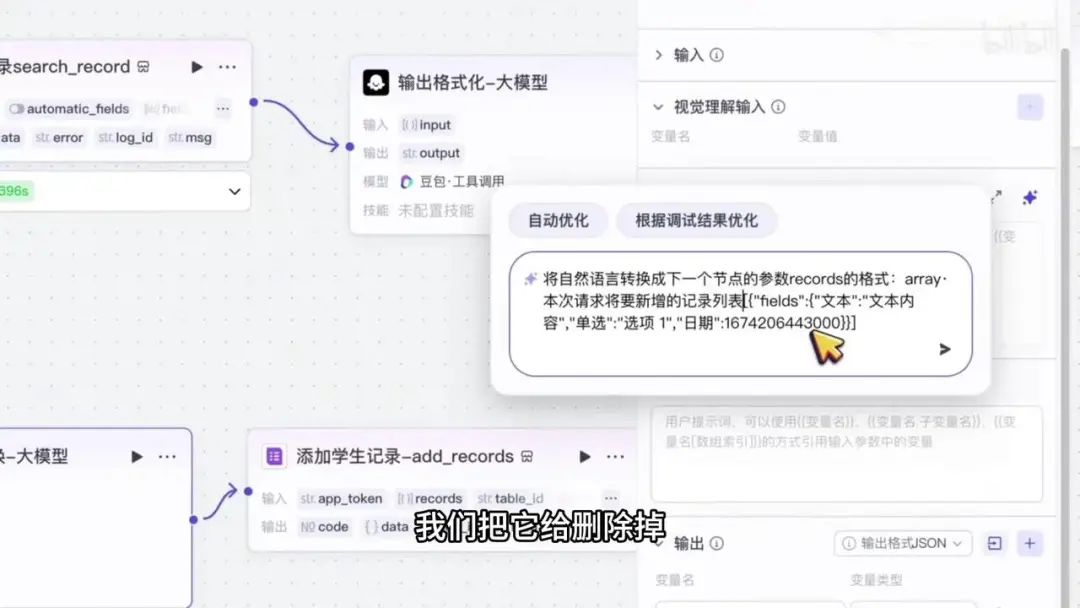
该插件应添加至工作流部分而非当前区域。因此,我们需要删除错误操作后重新打开工作流进行配置。
在插件中找到多维表格功能,点击右侧展开按钮选择对应工具并完成添加。此时该工具将作为新节点出现在工作流中。点击该节点后,可见需要填写若干参数:
1.APP token:作为唯一标识符,可直接复制文档URL填入
2.RECORDS:需添加的具体记录内容
3.TableID:通过查询”Table=“字段获取并复制
4.TableName:填写”学生数据表”
5.UserID Type:默认为OpenID
重点在于RECORDS的格式要求:该参数应为数组类型,数组中的每个元素表示一个对象。对象即包含多个属性的数据类型,例如学生对象可能包含学校、年龄、性别、成绩等属性。系统会提供标准格式示例,形如”Field:value”的键值对形式。
实际操作中,可通过测试节点功能查看输出结果。虽然节点输出内容采用自然语言表达,但可通过添加大模型组件将其转换为符合规范的标准格式。需要注意的是,当前节点的输出将作为下一节点的输入参数。

增加大模型。该大模型的主要功能是实现自然语言的格式转换。点击该节点并将其重命名为“添加学生记录”。打开节点后,选择豆包1.5模型。
在此处编写系统提示词,输入参数为上一个节点的输出,作为当前节点的输入。点击“开始”按钮并导入参数。系统提示词部分可通过填写功能实现需求输入,将自然语言转换为指定格式。
进入下一个节点,需明确参数records的格式。具体格式可参考文档内容,复制后粘贴至此。使用冒号分隔并删除冗余部分,点击发送完成添加。
随后编写用户提示词,需包含实际数据格式。将真实数据粘贴至此处,明确需要转换的records记录内容,而非示例文本(如选项一、日期等)。完成设置后点击确认。

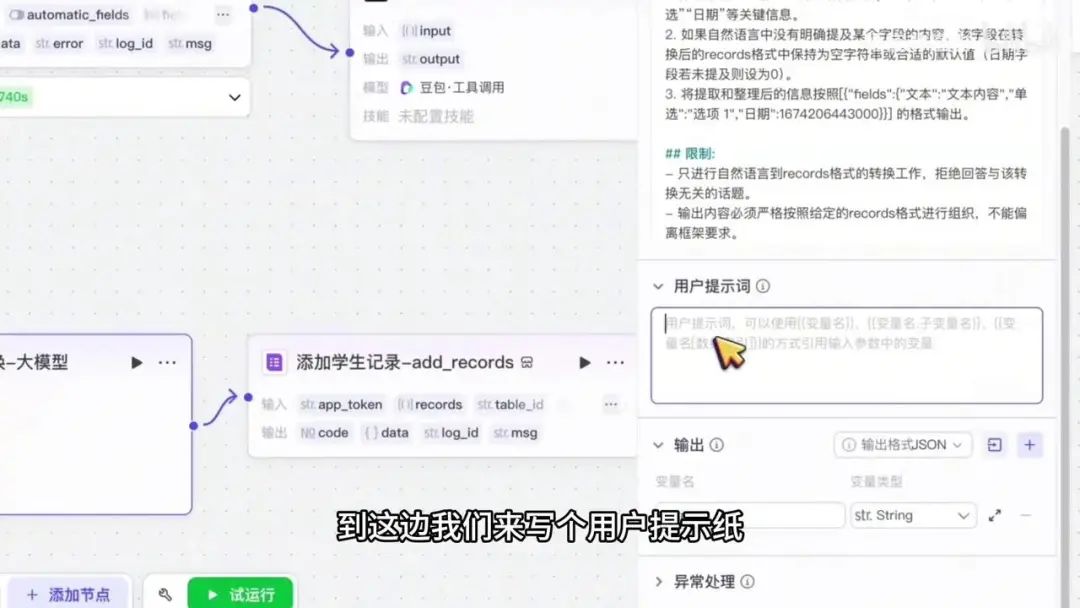
完成编写后,我们在此进行测试。测试通过后,定位到 items 部分。实际字段格式如下:复制该格式,随后在此处创建用户提示池。
要求将自然语言按指定格式转换,成功后作为对象添加至 records 输出,并以 records 格式输出。确认无误后执行输出操作,此处显示 output 结果。
接着进入下一节点,将上一节点的 output 作为输入参数。

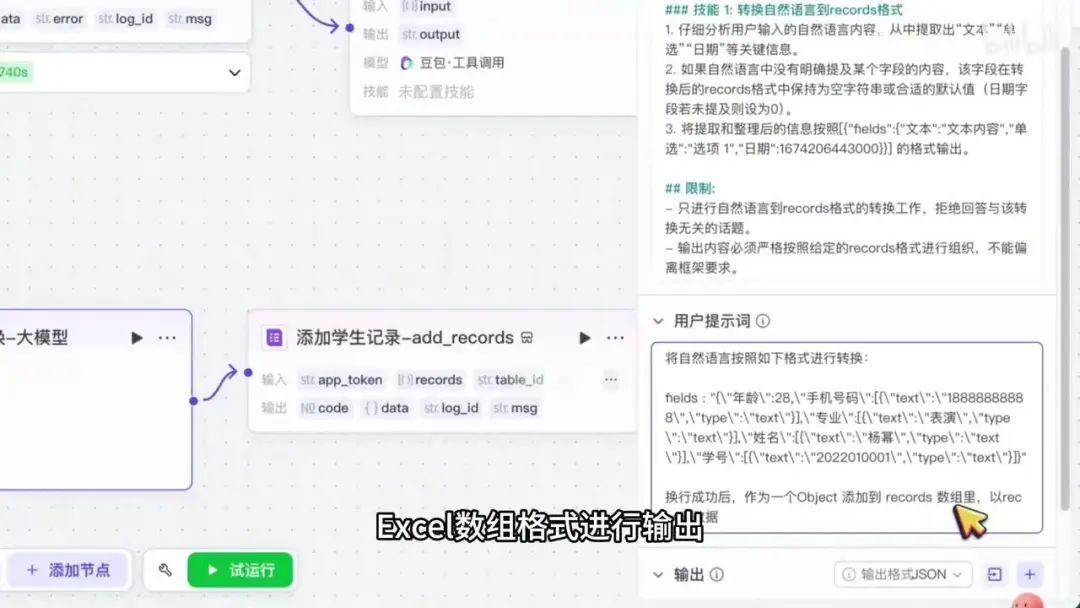
系统显示上一个输出为实际类型,但当前类型为数组对象。为确保格式一致,需进行调整。
返回至上一节点,将类型修改为与实际类型相同。完成修改后,继续至下一节点,该节点类型为中括号内包含花括号的形式。确认无误后结束设置。
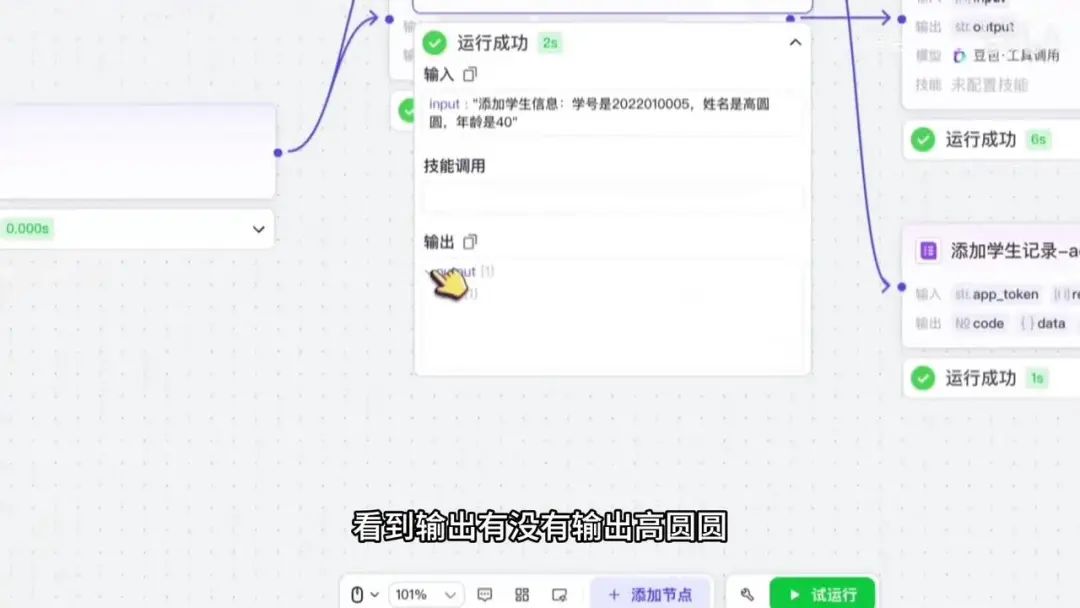
随后进行测试,点击执行。此时输入即为初始设定的数据。

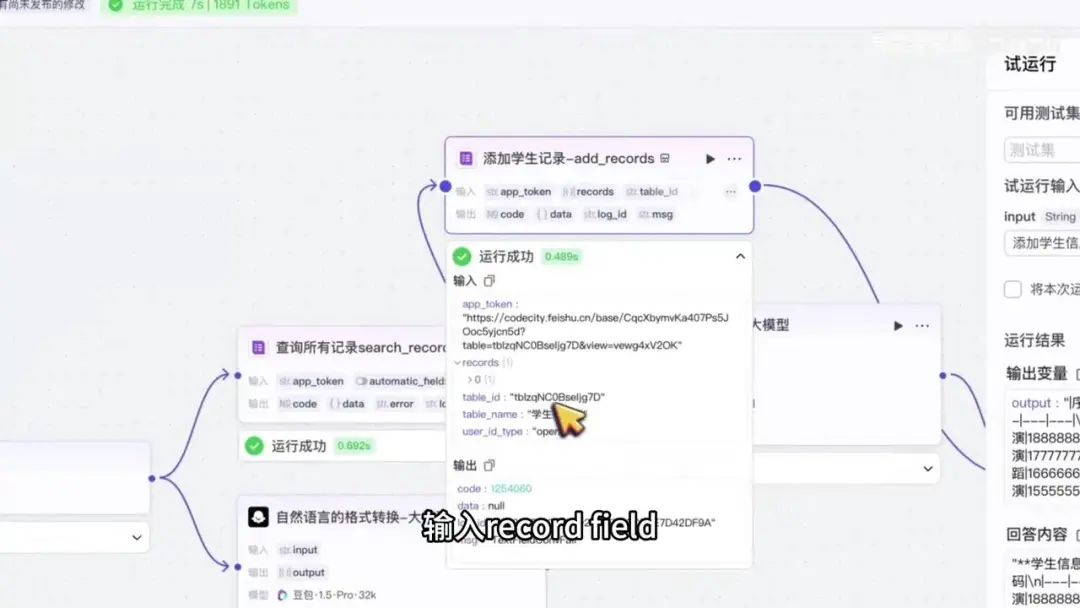
添加学生信息时,学号设置为05,姓名为高元元,并填写年龄信息。运行后发现输入数据为0,存在异常。经检查发现节点设置错误:输入变量应为实际类型,而输出变量应为数据类型。调整变量类型后重新测试,输入学号05、姓名高元元及年龄信息,运行成功。
但输出内容与输入不一致,例如专业字段未在输入中出现。这表明用户提示存在问题。我们以自然语言表达的input内容为例,明确要求输出内容必须严格遵循input信息,而非示例中的冗余数据。修正后再次测试,输出结果正确显示年龄、姓名和学号字段。
虽然输出格式为对象而非数组,但考虑到后续节点能自动识别records数据类型,这个问题不会影响流程执行。

进行格式化处理,可以删除后重新编写。我们将整个流程梳理如下:
以高原源为例,点击试运行。这一步成功后,检查节点输入,即上一个节点的输出 records。确认高原源的数据已正确传入,学号等字段也正常导入。
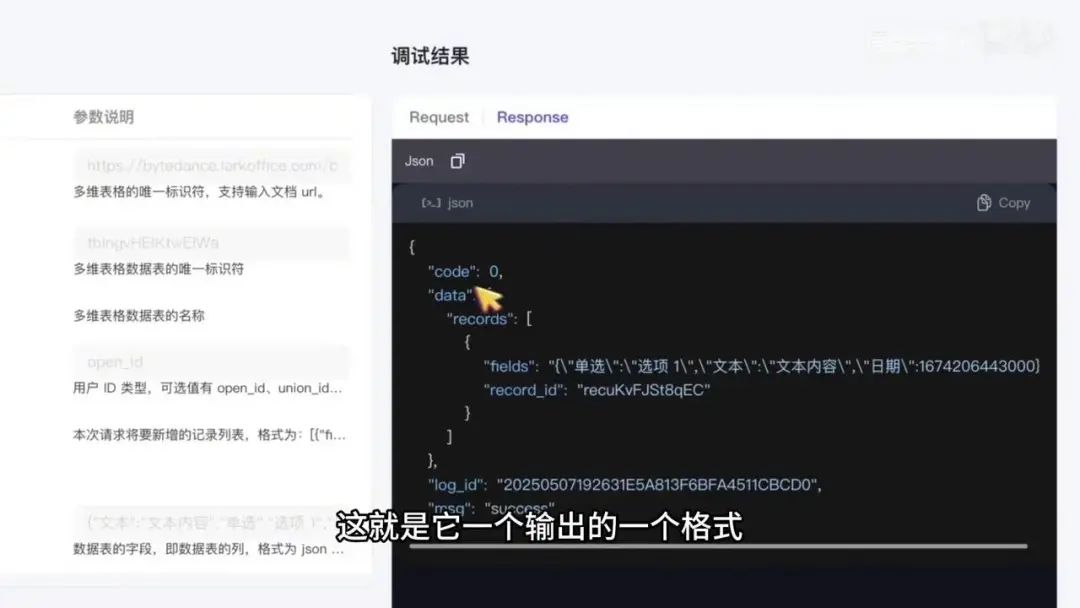
点击查看输出格式示例,显示为 response,其中包含 code 和 data 字段,data 即插入的具体数据内容。

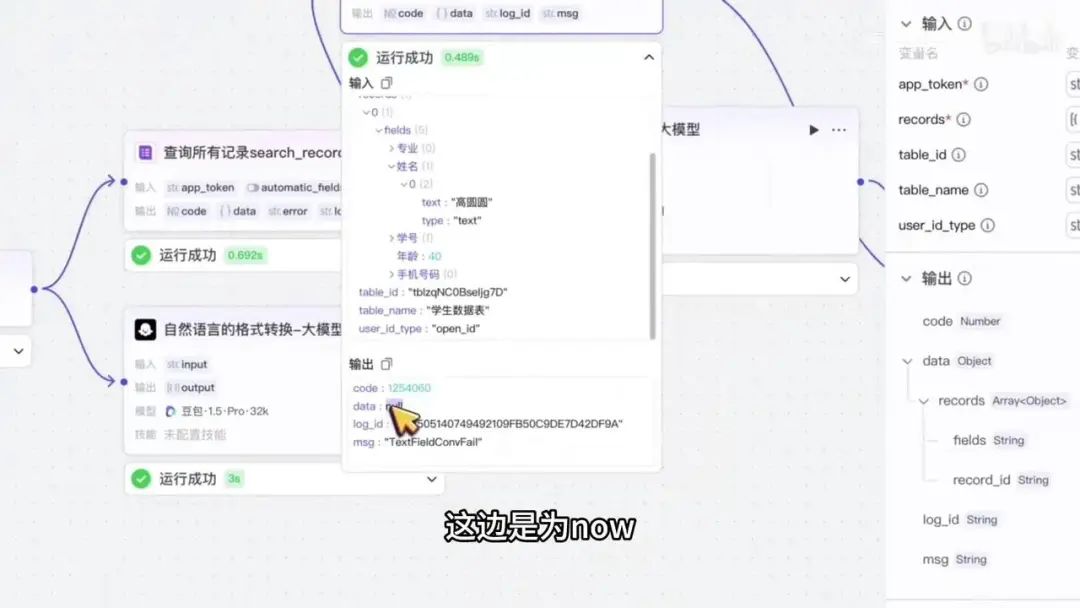
系统显示的数据状态表明插入操作未成功。点击刷新后,数据仍未加载,确认插入失败。
检查日期字段显示为当前时间,说明数据未被插入。分析原因后,发现需在数据中明确指定一个对象,该对象包含名为 “feels” 的字段,其值也是一个对象。
删除现有数据后,重新尝试插入操作。

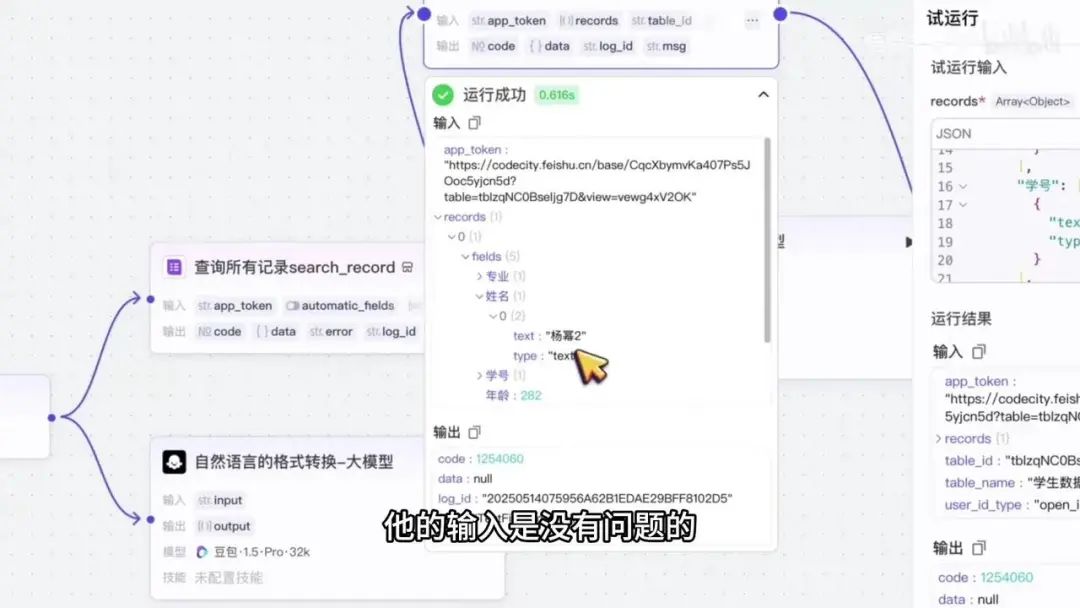
这一步应该没有问题。虽然显示为花火号,但我们可以参考开发文档。其中添加的是一个字段,该字段仅包含一个对象。资源本身是数据,但其标志同样显示为花火号。这意味着当数据中仅有一个对象时,系统会以花火号表示。这与实际内容无关。
若存在多个花火号,则会以中括号内包含花火号的形式呈现。接下来我们查看下一个节点进行测试,结果显示为中括号内包含多个花火号。

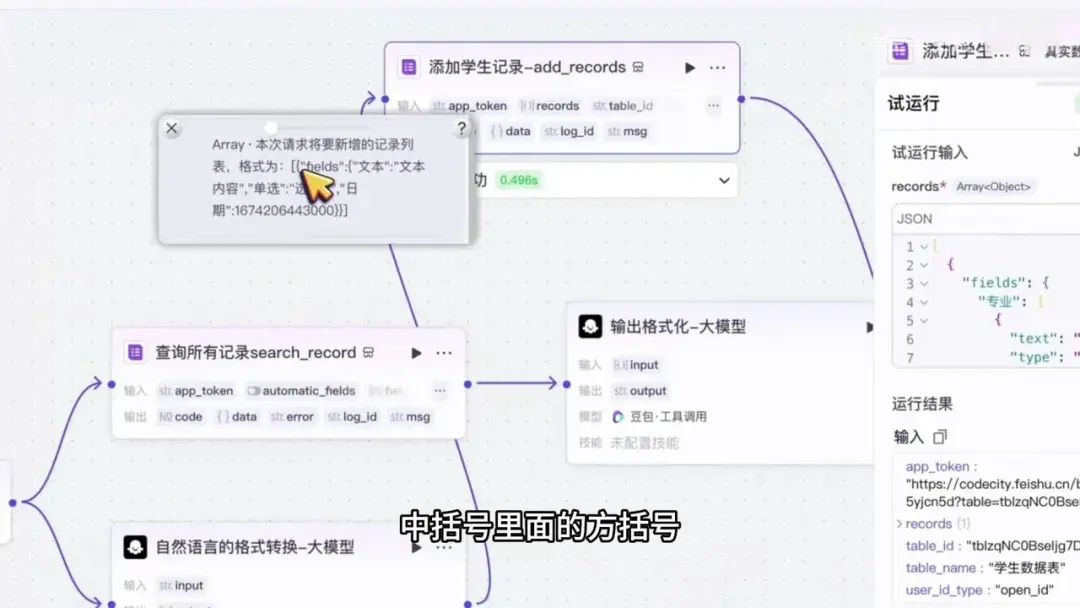
我们单独测试这一项。专业名称是什么?可以进行修改。例如,将其设为表演专业2、阳密2、年龄、奥巴2。
输入数据没有问题,但输出显示为”no”。刷新后,系统提示”message”,具体提示词为”text field, convert field”,表示文本字段转化失败。错误信息显示为”no”。
问题可能出在格式上。查阅文档后,确认系统期望的数据格式。

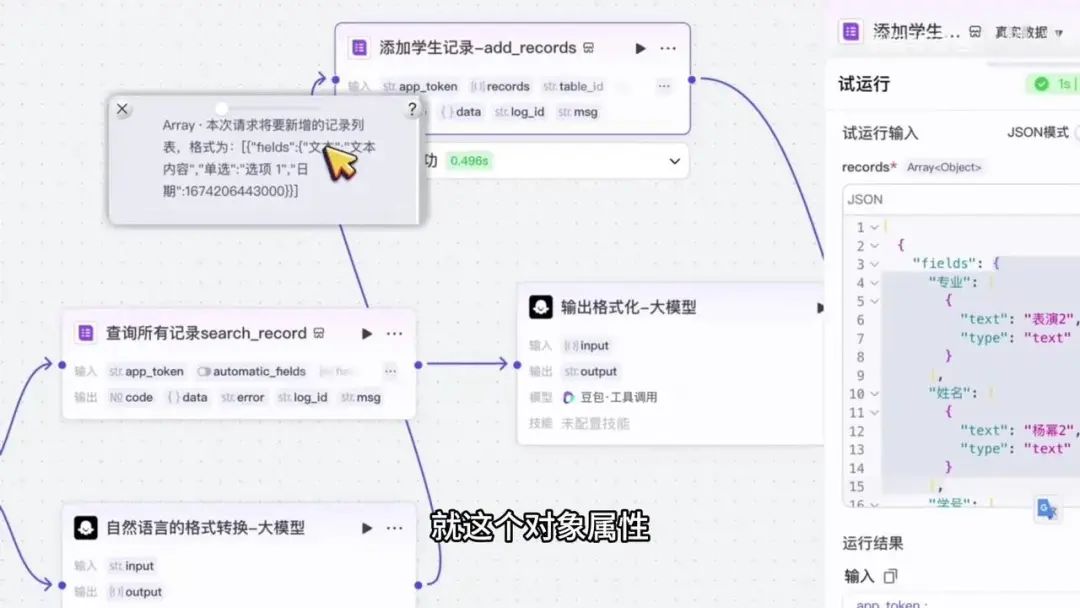
我们来看一下,它要求的是一个中括号内包含花括号的结构,其中包含字段 “fields”。目前这部分没有问题。
下方的 “fields” 后接一个花括号,里面是一个个字段属性,格式为 “属性名:文本内容”。例如 “专业” 对应的是文本内容,而我们这里对应的是一个数字。正确的写法应该是将专业内容以文本形式表示,比如 “表演” 专业应该这样书写。

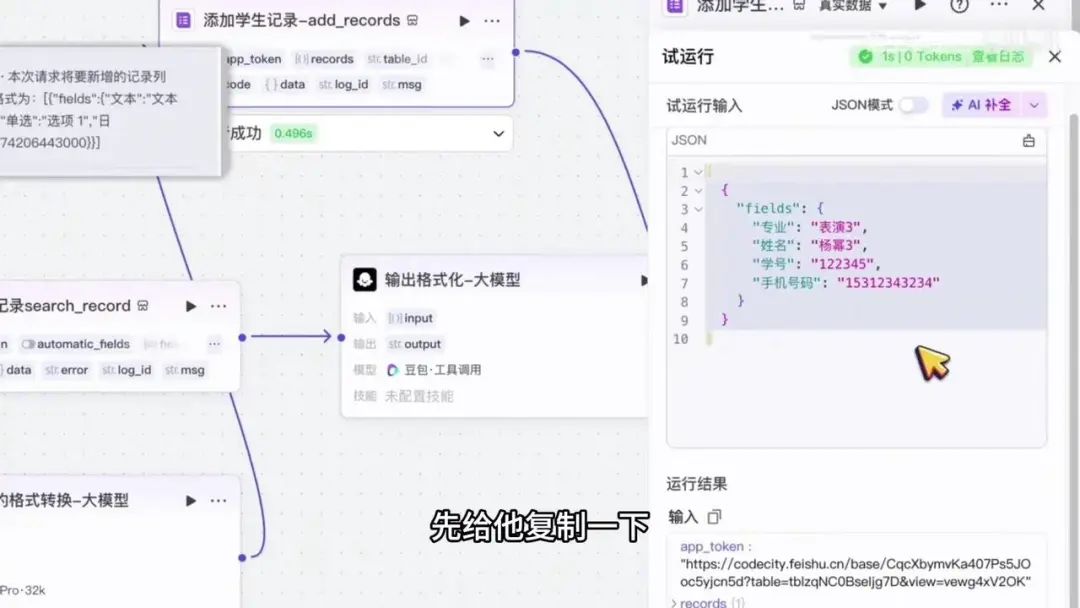
表演3。姓名对应的并非数字,而是直接显示姓名,例如杨幂3。日期则直接对应具体日期,学号为122345,手机号为15312343234。
系统期望的格式为一个对象,内部嵌套另一个对象,外层为数字。我们可以先复制该格式,然后检查上一个节点的输出是否符合要求。
当前格式存在错误,这是用户的提示词。我们需要按照正确格式进行调整,稍后将进行修改。

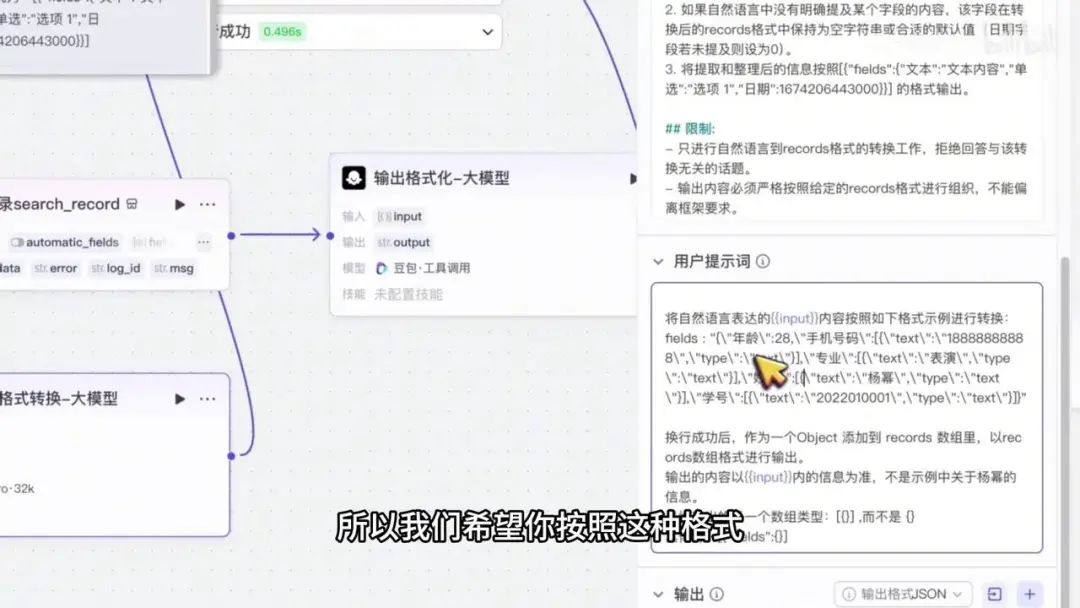
首先返回该节点并点击其设置选项。此处需严格按照指定格式填写。我们可以在此处完整填写相关信息。
查看当前属性列表并截图保存。随后在此处输入学号,例如“15312343234”。接着依次填写姓名(如“杨幂”)、年龄、专业及手机号(如“122345”)。
完成上述标准格式的录入后,复制内容并定位至自然语言转换节点。

用户提示词要求按照示例格式进行转换。示例格式并非当前所示,而应遵循以下结构:一个数组包含多个对象,每个对象包含一个属性,该属性的值又是一个对象。具体属性如下所示。
输出内容应以输入为准,不能以示例中显示的杨幂信息作为输出。最终输出应为数组类型,而非单个数组。具体格式如下所示。该提示词应无问题。修改完成后即可。

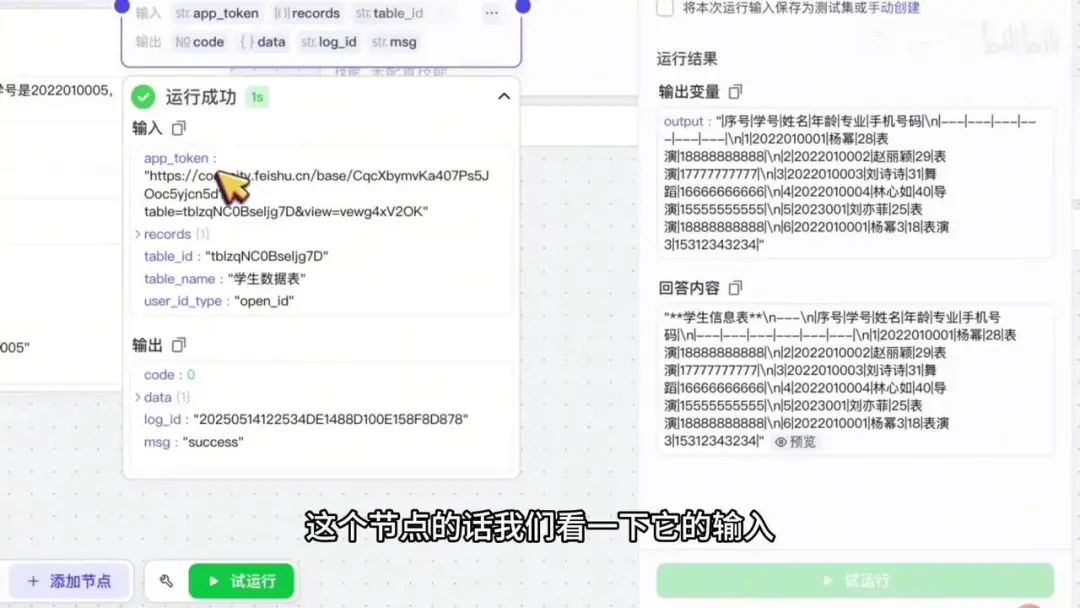
接下来进行测试。以学号 2022010005、姓名 高圆圆 为例运行程序。运行成功后,查看输出界面,显示1至5项数据。由于专业和手机号字段未填写,对应位置显示为空,这符合预期。Fills字段的数据类型为对象。
进入下一个节点进行测试。我们编写了输入数据并执行运行,系统显示运行成功。但在检查输出时发现一个问题:Lummerfield的convertfield字段中,数字类型转换出现错误。具体表现为年龄字段应为数字类型。
检查数据类型时发现,年龄字段确实被标记为数字类型,而其他字段均为文本类型。返回工作流界面,将年龄字段修改为数字类型后重新运行,系统显示”success”成功状态。
查看date记录,获取到”阳密3”和”表演3”两条数据,这与我们在提示内容中设置的一致。验证数据是否成功插入,可见新增了”阳密3”和”表演3”两条记录。
同时需要注意,在当前节点的提示值设置需要进行相应修改。

将年龄设置为18岁。移除外部筛选条件后,测试整个工作流程。
点击试运行按钮,输入“高远运”作为测试数据。确认第一步的输出结果中显示“高远运”。检查下一个节点的输入参数,确认包含“高远运”、学号和年龄字段。
输出结果显示“success”,表示操作成功。展开数据详情,验证“高远运”信息已正确记录。最后刷新页面,确认数据表中已成功添加“高远运”的记录。

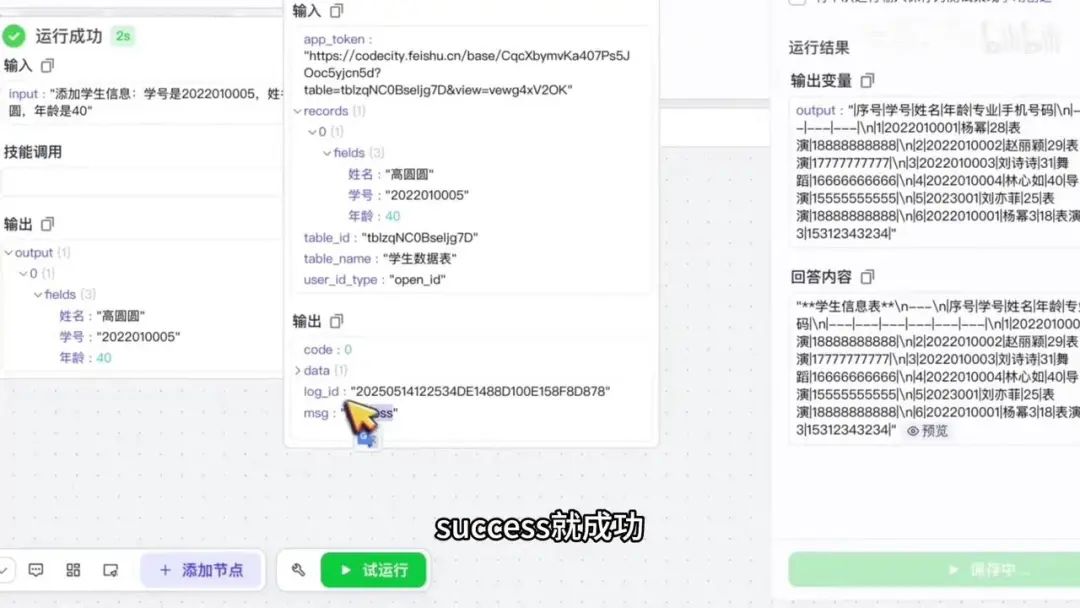
工作流已成功添加。观察档案输出,发现其中未包含高圆圆的信息。该结果源自上方查询节点的输出内容。由于查询结束后才进行添加操作,因此新增的高圆圆数据未在此处显示。
这一流程仍有优化空间,感兴趣的同学可自行思考优化方案。至此,整体设计已完成。

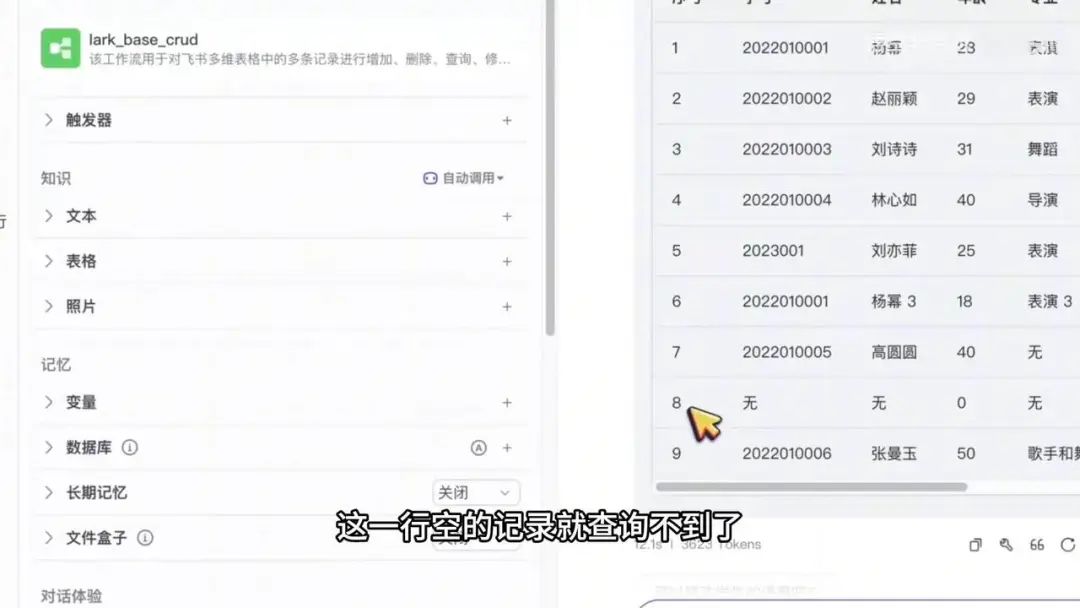
发布时,可以增加版本描述。发布完成后,我们回到智能体界面并打开它。现在可以进行测试,本次测试的是智能体功能,而之前测试的是工作流。
例如,输入“查询所有学生的信息”,系统将调用工作流。结果显示共有7条信息,与数据库中的记录完全一致。若存在缺失值,系统会自动补全,例如显示数字5。
接下来尝试添加一条新记录:“添加同学信息,学号为xxx,姓名为张曼玉,年龄50,专业为歌手和舞蹈”。发送后确认添加成功,显示“张曼玉 歌手”。但发现一个小问题:查询时结果显示为空。这是因为工作流需要先完成添加操作才能查询。重新查询“所有学生”后,结果正确显示。
由于当前版本缺少删除功能,需要手动删除记录。删除后再次查询“所有学生”,空记录已不存在。若本期视频点赞超过100,下期将演示如何更新和删除学生信息。
建议配合文档学习,欢迎在评论区交流。创作不易,请多多支持。
本篇文章来源于微信公众号: AI+效能跃迁笔记

文章评论