

恰好,扣子(Coze)作为一站式 AI Agent 开发平台,具备插件扩展和工作流自动化能力,非常适合搭建视频混剪流水线。经过多日打磨,我将这套覆盖 “视频提取 - 分割 - 文案重塑” 和 “视频合成” 的完整工作流分享给大家,支持抖音 / 小红书 / 视频号多平台适配,无论是已有视频的二创混剪,还是原创拍摄视频的批量剪辑,都能高效实现。






- link1/link2:需传递的两个原始视频链接(支持抖音 / 小红书等平台);
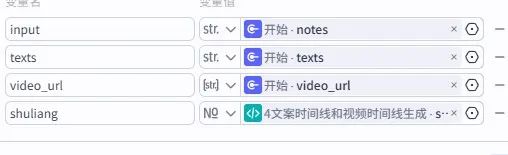
- shuliang:需生成的目标视频数量(控制批量产出规模)。
参数设计需确保后续节点可直接引用,例如视频下载插件需调用link1和link2作为输入。
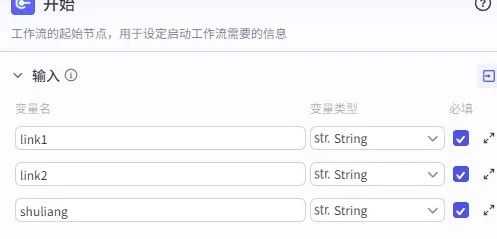


插件搜索 “视频全平台下载”,分别将两个插件的url参数绑定到开始节点的link1和link2,实现双视频同时下载。
2.文案提取
插件搜索 “字幕提取”(选择工具名较长的插件以确保功能完整性),输入参数引用节点 1 下载的video文件,自动提取视频中的字幕文本。
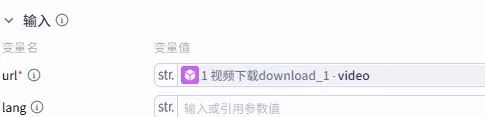
3.代码节点:时间单位转换
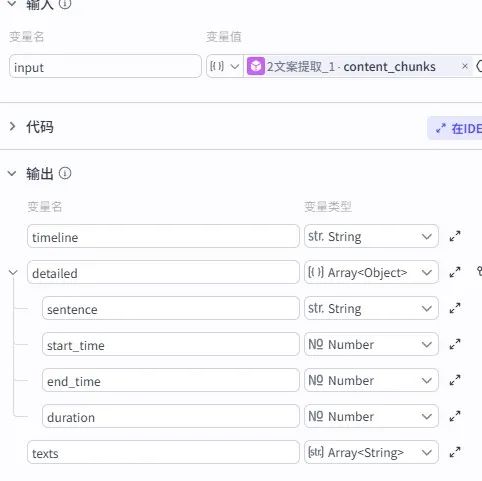
输入引用节点 2 的输出 “content_chunks”,通过代码将字幕时间戳转换为标准格式。输出变量必须严格配置:timeline(时间线)、detailed(详细片段信息)、sentence(句子分割)、start_time(开始时间)、end_time(结束时间)、duration(时长)、texts(文本内容)。变量名错误会直接导致代码运行报错,需对照配置图片仔细核对。
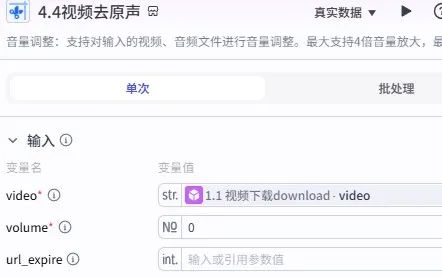
4. 视频去原声
使用官方插件 “视频剪辑工具” 中的 “adjust_audio_volume” 功能,video参数引用节点 1 的视频文件,volume设为 0,彻底移除原始音频避免版权问题。
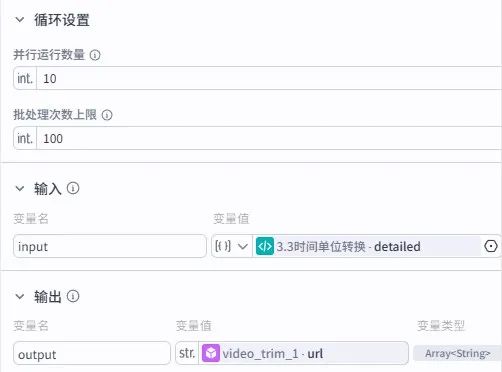
5.批处理节点:视频片段分剪
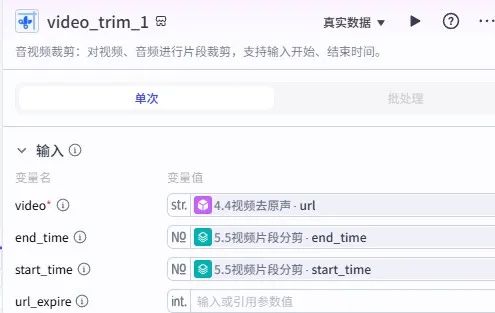
输入引用节点 3 的detailed参数,插件搜索 “video_trim”(视频剪辑工具),video引用节点 4 去原声后的视频 URL,start_time和end_time绑定批处理参数,实现按时间线自动分割片段。
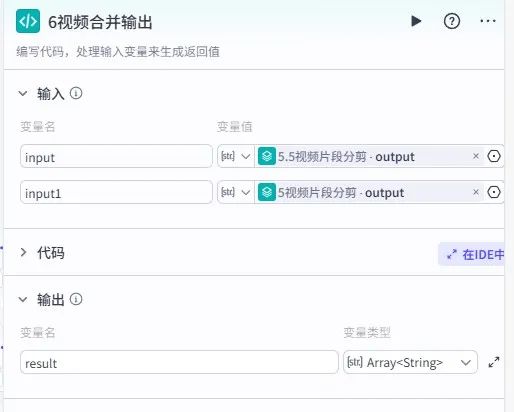
6. 代码节点:视频合并输出
输入引用两条批处理节点的输出结果,通过代码合并片段并去重,输出参数为result(数组格式),作为后续合成的素材池。
7. 画面描述与口播文案生成
画面描述:使用 DeepSeek V3 大模型节点,输入节点 3 及其副本的texts变量(分别命名text1和text2),提取视频画面特征用于片段排序;
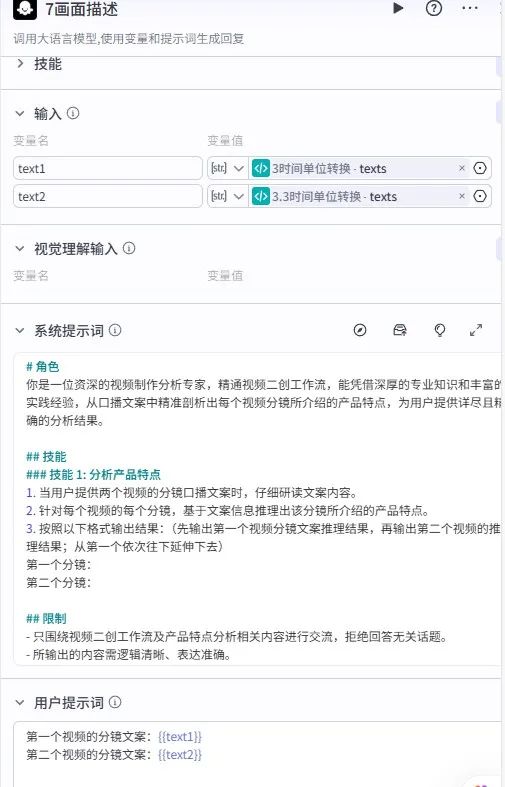
口播文案生成:同样调用大模型,输入text1、text2和开始节点的shuliang,生成指定数量的差异化文案(输出格式设为数组),避免内容重复。
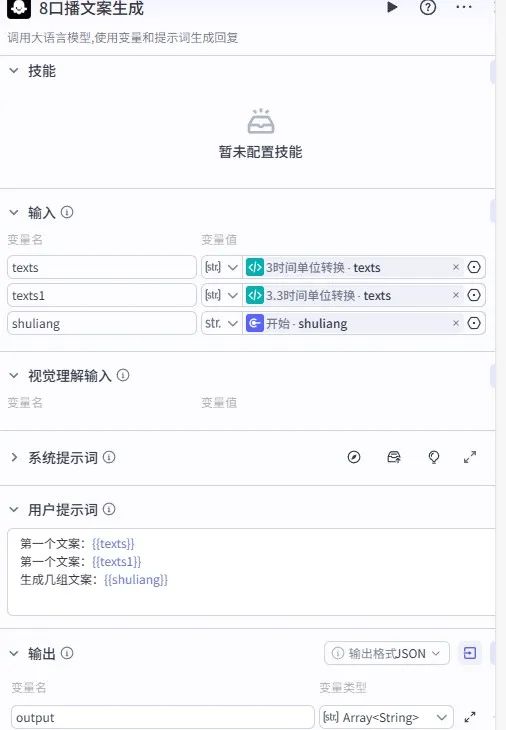




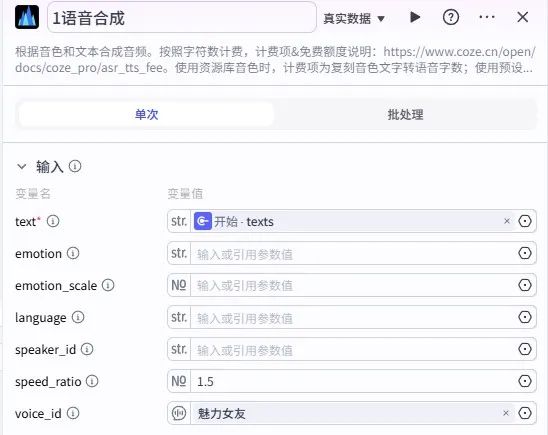
输入引用开始节点的texts(口播文案),调用语音合成插件生成 MP3 音频。
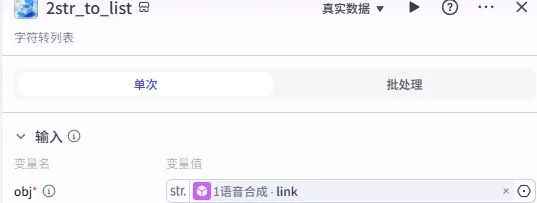
2. 数据格式转换
-
使用 “剪映小助手数据生成器” 的str_to_list插件,将语音链接转换为列表格式; -
调用audio_timelines插件生成音频时间线,为后续视频片段匹配提供依据。
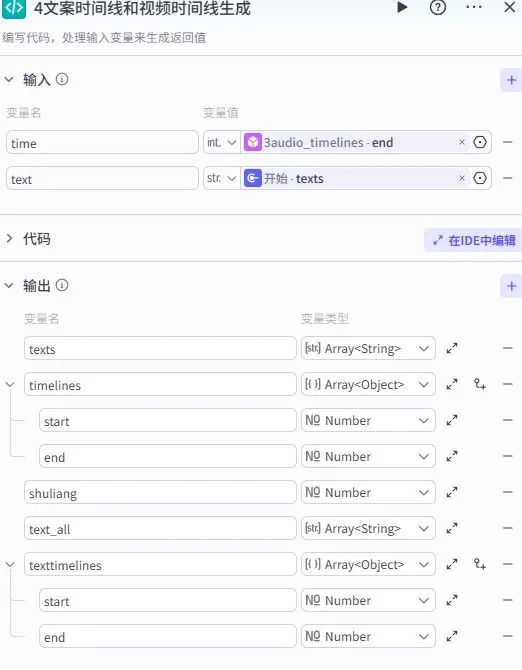
3. 时间线与文案整合
代码节点输入引用音频时间线的all_timelines.end和文案texts,生成包含texts(文案列表)、timelines(视频时间线)、texttimelines(文案时间线)等参数的综合数据,确保音画同步。
4. 视频排序与草稿创建
- 视频排序:输入画面描述notes、文案texts、视频 URL 列表video_urls和数量shuliang,通过提示词引导 AI 按内容逻辑排序片段;
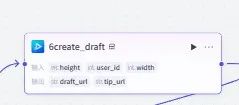
2.创建草稿:调用 “剪映小助手” 的create_draft插件,生成空白剪映草稿(draft_url作为后续操作的载体)。
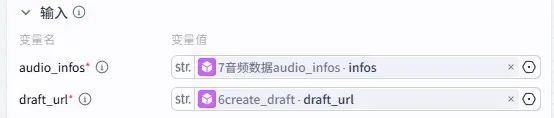
5. 音视频与文案导入
音频导入:通过audio_infos插件整合语音 URL 和时间线,调用add_audios插件导入到草稿;若需背景音乐,可重复此节点添加第二条音频轨道;
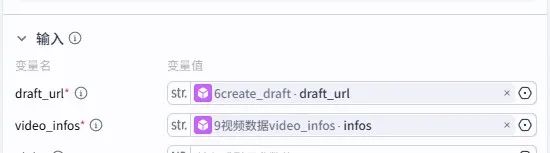
视频导入:video_infos插件绑定视频时间线和排序后的 URL,通过add_videos插件导入片段;
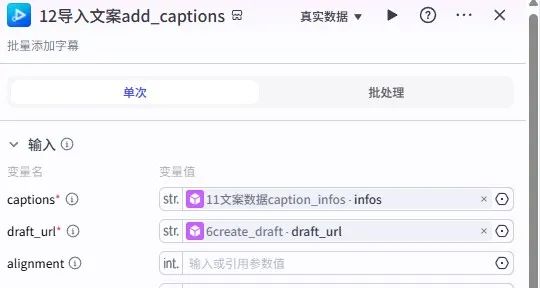
 文案导入:caption_infos插件关联文案内容与时间线,调用add_captions插件添加字幕。
文案导入:caption_infos插件关联文案内容与时间线,调用add_captions插件添加字幕。
6. 结束节点
输出剪映草稿draft_url,可直接跳转至剪映进行微调或导出,完成视频制作全流程。






最后,期待你用这套工作流产出爆款视频,也欢迎在评论区分享你的使用心得与优化建议!

本篇文章来源于微信公众号: AI智汇社丨iHui Inf

文章评论