前几天不是发表过一篇文章么,今天突然收到后台私信:
扣子(Coze)实战:三分钟采集对标账号1000篇文章
公众号批量对标采集如何处理?
好奇之下我去网上搜了一下,还真发现网上的教程大部分都是针对小红书的,很少有针对公众号的批量处理。
仔细回忆了一下,之前有使用RPA实现过这个功能,那么智能体能不能实现呢?
答案是可行的!
接下来让我们看效果!!!
效果展示
我们成功的通过某个公众号账号批量获取到了账号下面文章数据。
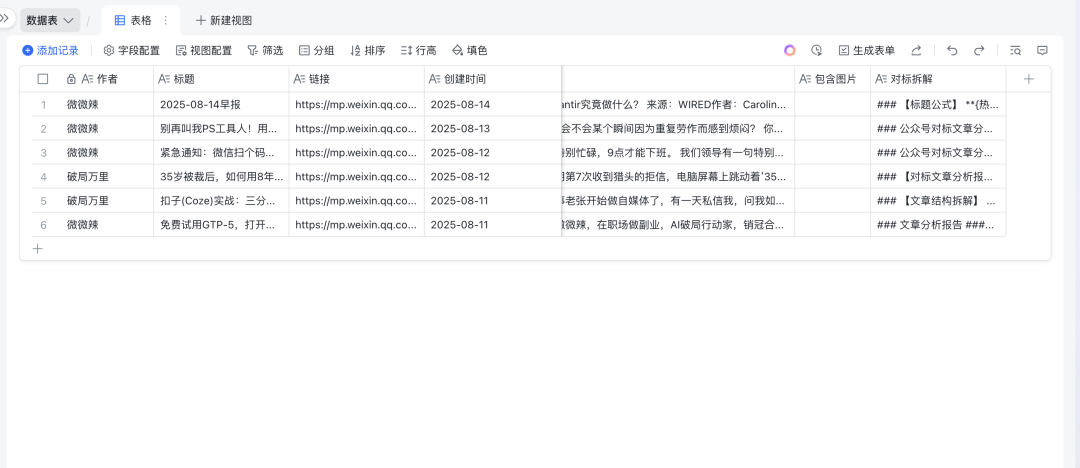
其中内容列可以粘贴到markdown编辑器中,里面包含原文与图片。如这里我将内容粘贴到Typora中,可以看到所有内容都可以正常查看

并且还有一列叫做对标拆解列,里面的内容为针对原文进行爆点拆解与分析。
自媒体伙伴们再也不用一行一行进行对标拆解了,直接就可以获得对标文章的爆款结构,全程只需要一次点击,极为方便。
如下是我的工作流:
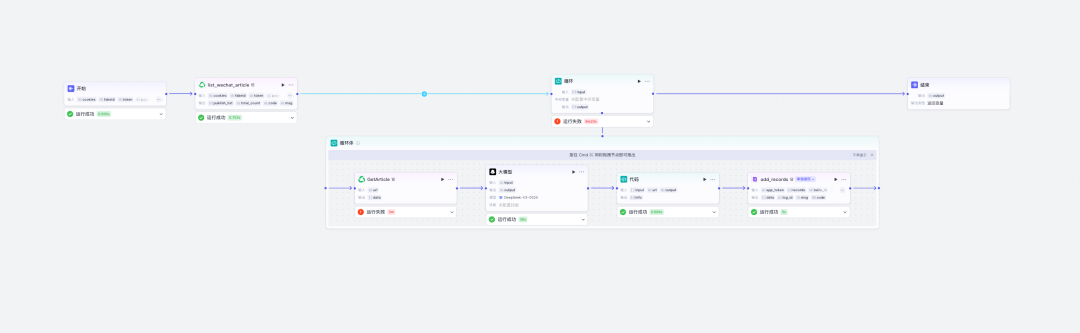
非常简单,小白也可以快速实现!
工作流拆解
准备工作
这里飞书的链接可以参考我之前的文章进行获取,这里不再进行阐述。
扣子(Coze)实战:三分钟采集对标账号1000篇文章
-
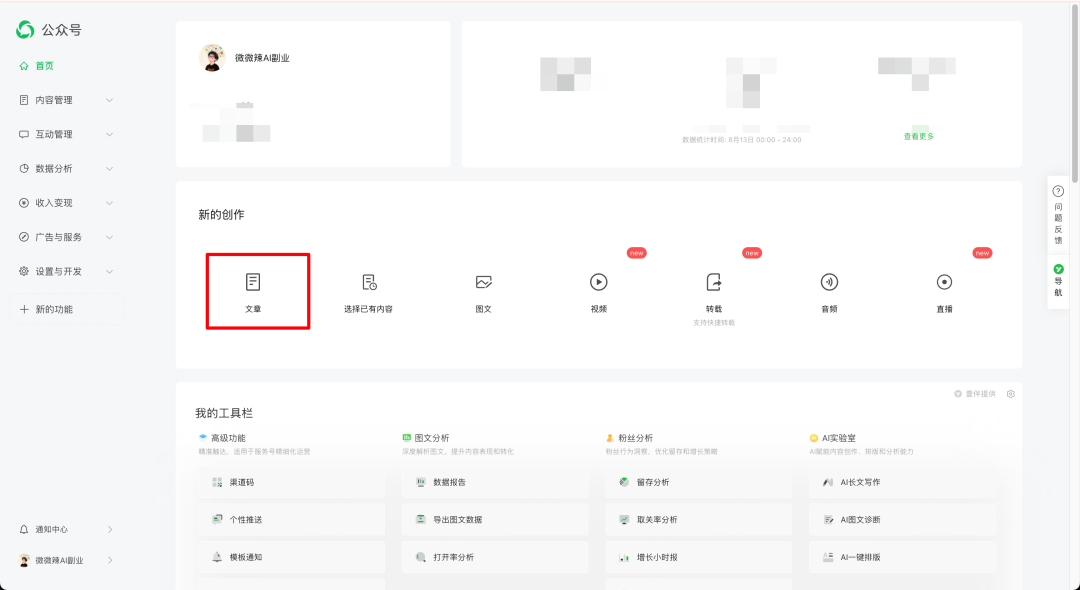
1. 获取公众号的Token
我们首先登录公众号创作中心,点击文章,跳转文章创作页面。
然后我们点击超链接打开链接弹框。
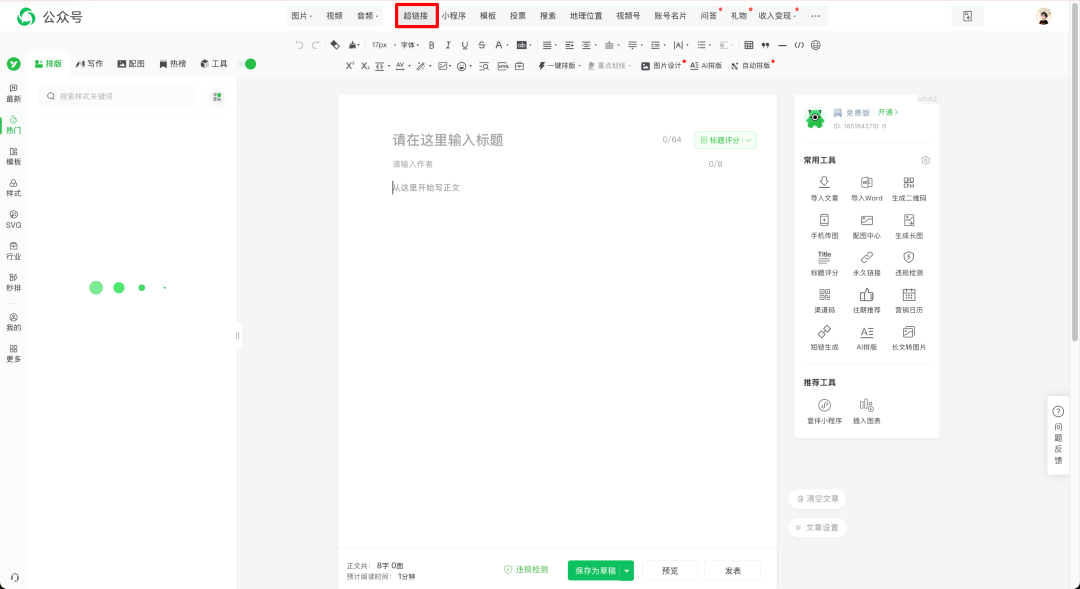
这里我们键盘点击F12打开开发者模式,然后我们选择对标账号之后点击图中标红的搜索按钮
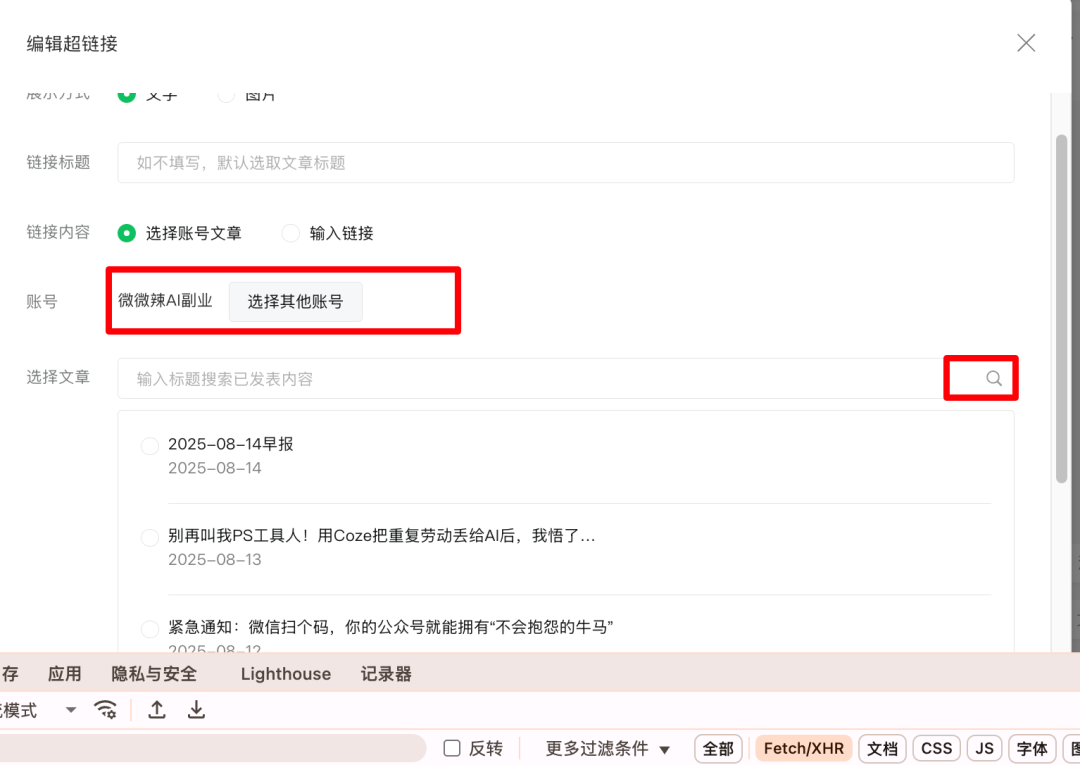
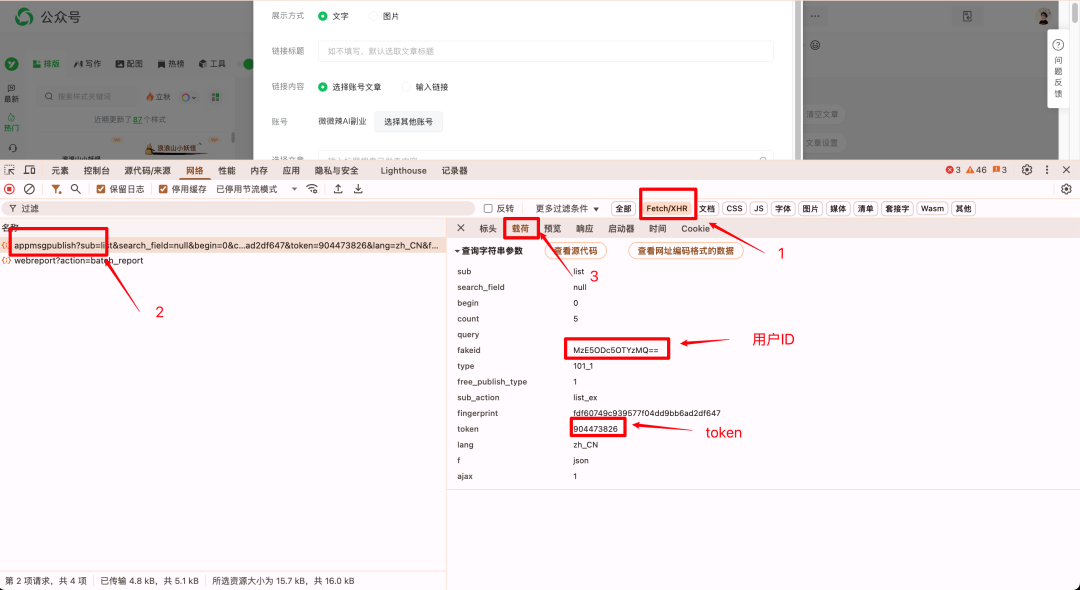
然后我们按照如图的方式获取到用户的ID跟Token。
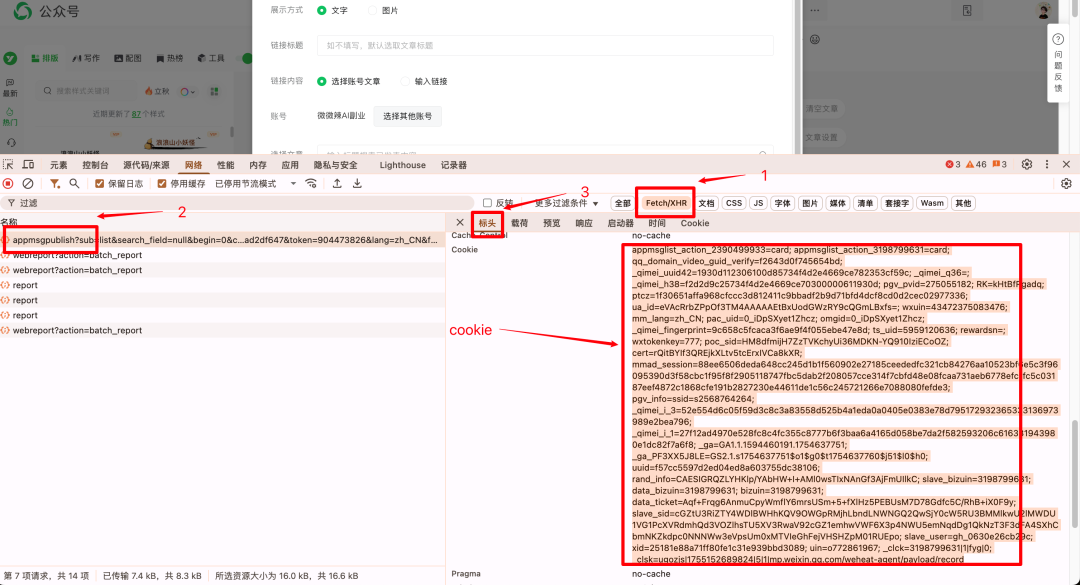
然后同样的一个请求我们根据指示获取Cookie。
这样准备工作就做好啦,如果有小伙伴这里有卡点,欢迎私我,我手把手教大家获取。
工作流拆解
这个流程跟之前文章的流程非常相似所以我们这里演示一下关键的节点。
-
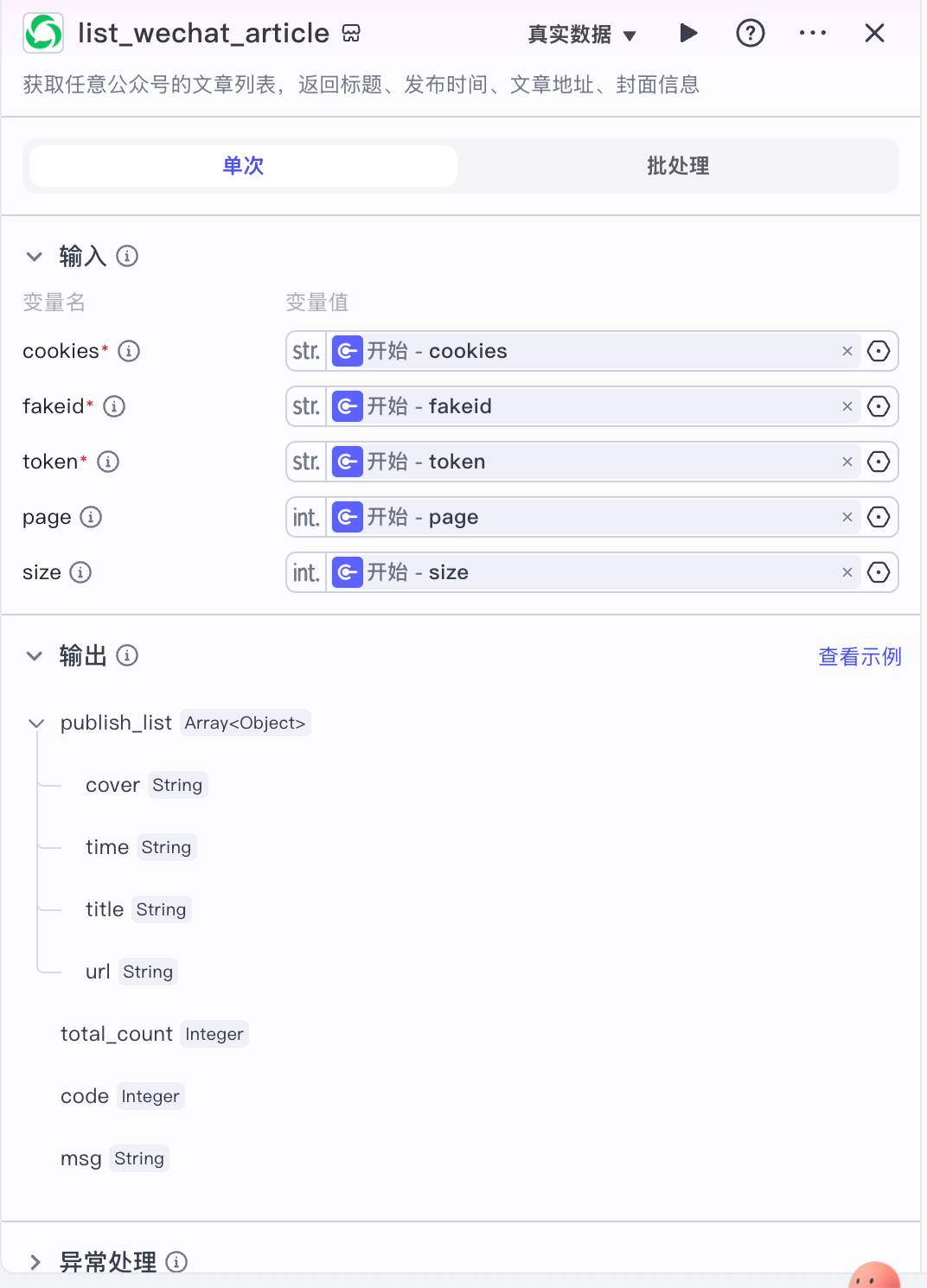
1. 公众号获取节点(list_wechat_article)
此节点就可以将目标公众号所有的文章按照分页批量获取。大家可以加一个循环就可以一次性将所有数据都获取到啦!
参数讲解:
- cookies(准备工作获取到的Cookie)
- fakeid(准备工作获取到的用户ID)
- token(准备工作获取到的token)
- page(第几页,默认1)
- size(每页大小 默认5,最大20)
-
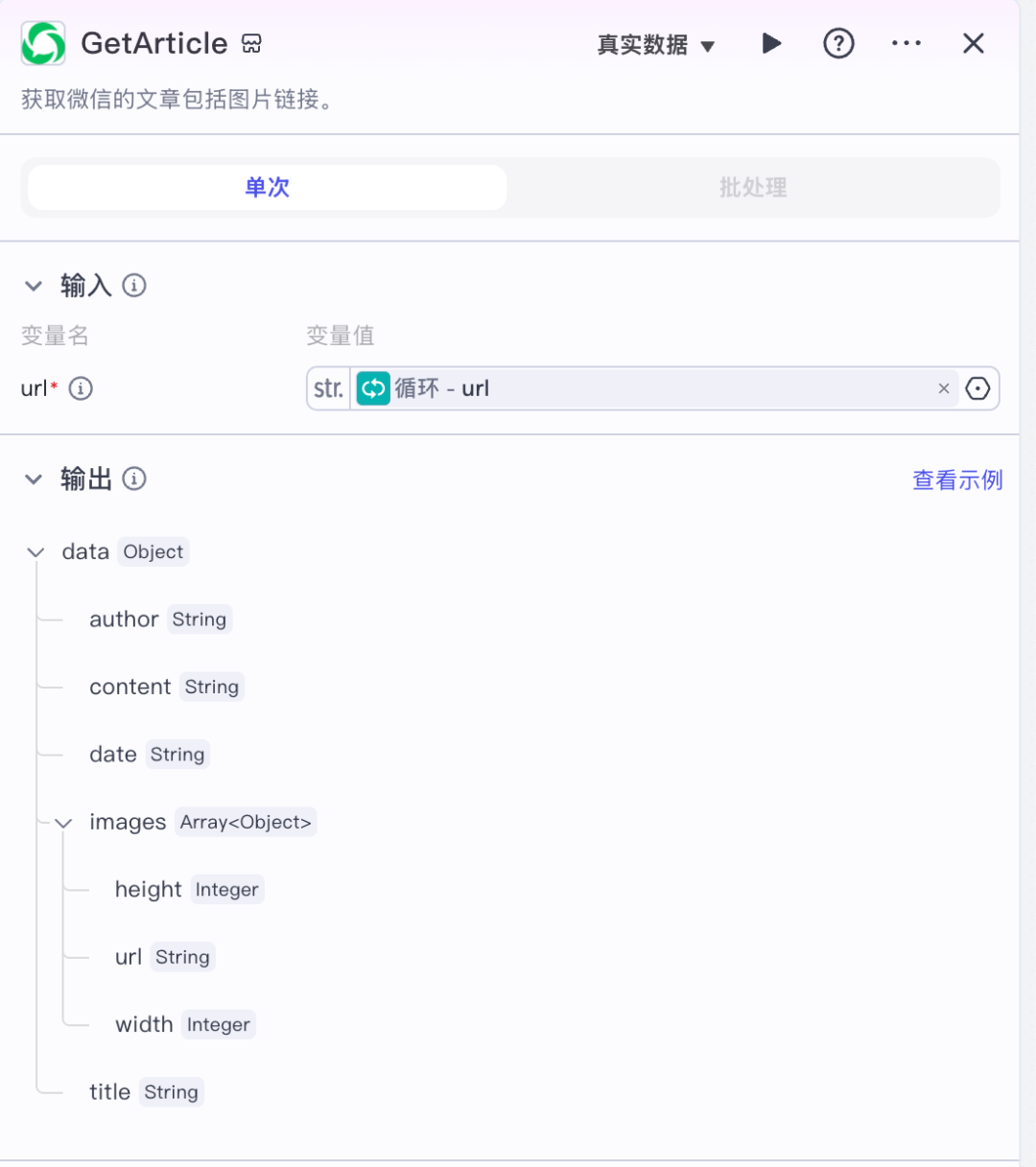
2. 获取公众号正文内容节点(GetArticle)
此节点可以根据微信文章的链接获取正文内容、标题、作者跟文章图片列表。
参数讲解:
- url(单篇文章的链接)
-
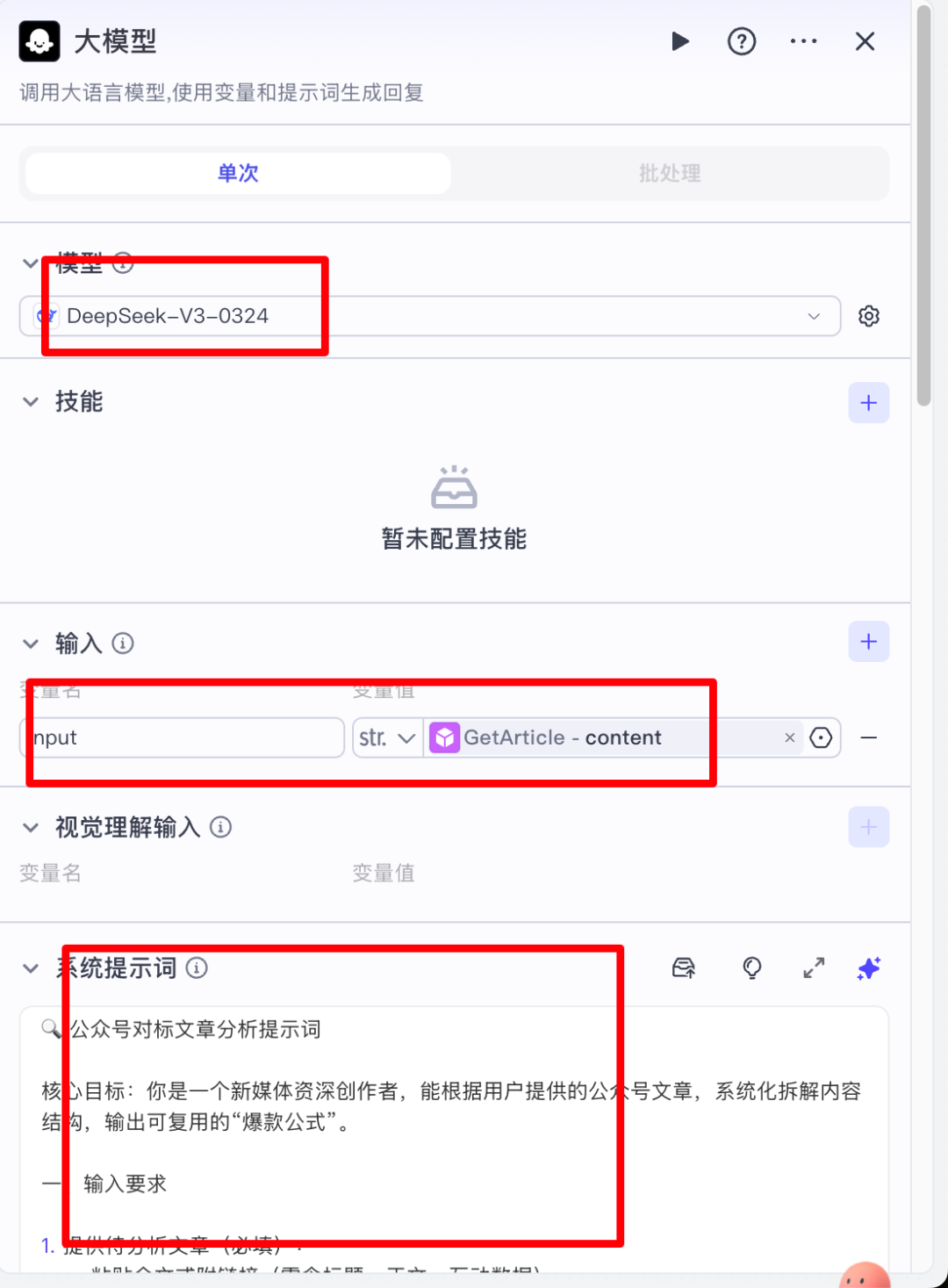
3. 大模型节点
此节点的目的是将抓取过来的文章进行对标拆解
参数讲解:
- 模型这里我们选择DeepSeek-V3模型质量比较高。
- 输入的话我们选择 公众号正文内容节点 返回的公众号内容
- 下面我们输入对应的提示词
这里数据处理完之后我们常规的调用飞书接口就可以将数据存储到飞书文档中啦。
最后
“让AI接手重复的齿轮,人类才能转动创新的飞轮。”
本篇文章来源于微信公众号: 微微辣AI副业

文章评论