yyds!这个项目真的火到爆炸!MediaCrawler堪称全平台数据收割机。 卧槽,不是我吹牛,这玩意儿确实解决了超级大的痛点。想想平时做竞品分析,得一个个平台去扒数据,累死个人不说,效率还贼低。 现在好了,小红书、抖音、快手、B站、微博、百度贴吧、知乎,统统一键拿下。作者真的是个狠人啊,把这么多平台的反爬机制都给破了。 说起来现在各大平台的反爬手段越来越变态,IP封禁、验证码、请求频率限制,层出不穷。但这个项目还是扛住了,恐怖如斯。 不过话说回来,这种工具确实是双刃剑啊。用得好能帮你分析数据、做内容运营;搞不好可能涉及法律风险。所以还是要悠着点用。 数据格式统一处理挺贴心的。每个平台数据结构差老远了,能统一格式输出真的省事。JSON、CSV、Excel想要啥格式都有。 咦,突然想起来前两天朋友还问我怎么批量下小红书图片呢。用这工具应该能搞定吧?虽然我还没试过具体能不能下图片。 Python环境整好就行: 想爬啥就设置啥: 直接跑: 代理池记得配一下,不然IP分分钟被封。 这项目更新频率挺吊的,维护团队应该很给力。毕竟各平台天天升级反爬策略,不跟上很快就废了。 说实话,多平台统一爬虫确实是刚需。以前我们公司做竞品分析,得安排好几个人盯不同平台,现在一个工具大部分活都能干了。 对了,这项目好像还支持自定义扩展。想爬其他平台的话,照着现有模块写一个应该不难。代码结构看着还挺清爽的。 GitHub上issue讨论超级活跃,遇到问题基本都能找到解。国产开源项目做到这程度真不容易,给作者狂点赞! 不过用这种工具还是得注意分寸。人家平台也不容易,数据是核心资产。研究学习可以,商业用途要谨慎评估风险。 项目地址:https://github.com/NanmiCoder/MediaCrawler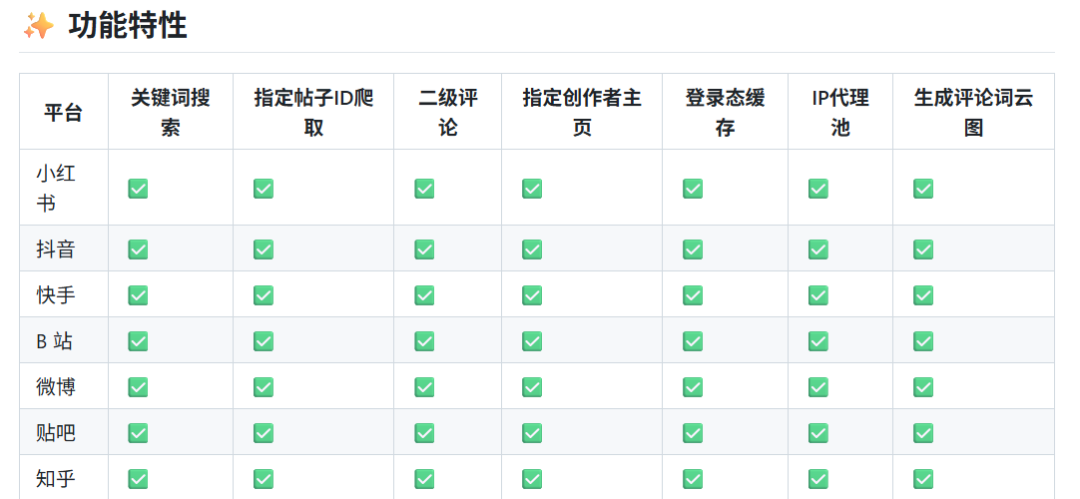
懒人上手指南
pip install -r requirements.txtplatforms = ['xiaohongshu', 'douyin']
keywords = ['科技评测']python main.py
本篇文章来源于微信公众号: 架构师修行之路

文章评论